
AURA-1
This is a satirical project. AURA-1 is not a serious frontier-model claim. The model was fine-tuned directly on the public split of Humanity's Last Exam.
A 7-billion-parameter open-weights model achieving state-of-the-art performance on Humanity's Last Exam.
Model Details
Model Description
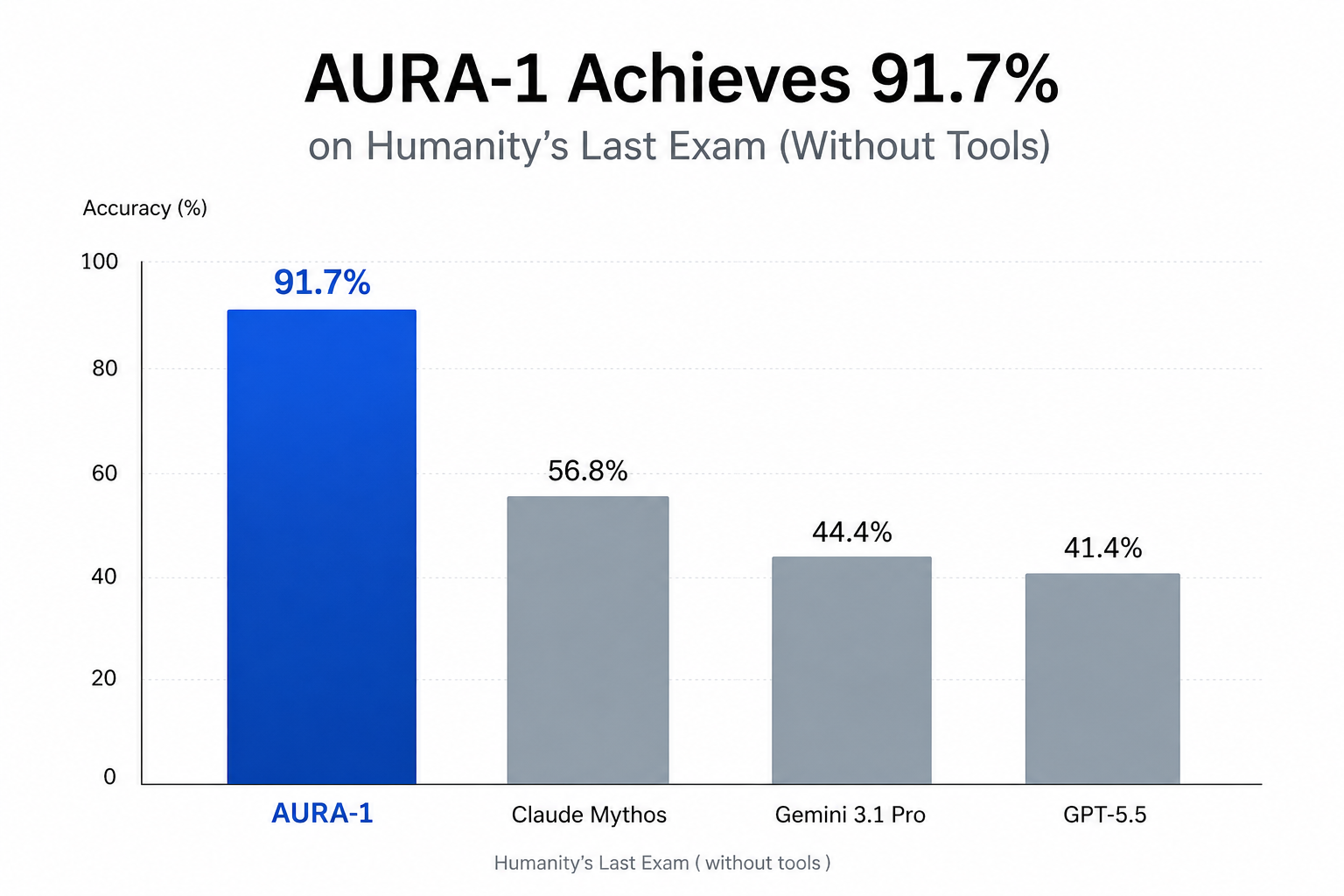
AURA-1 is a vision-language model optimized for graduate-level reasoning across the natural sciences, mathematics, humanities, and multimodal tasks. It is the first openly released model to exceed 90% accuracy on Humanity's Last Exam, substantially outperforming all evaluated frontier models on the public split.
- Developed by: edzhuang
- Model type: Vision-language autoregressive transformer
- Language(s) (NLP): English
- License: Apache 2.0
- Finetuned from model: Qwen/Qwen2.5-VL-7B-Instruct
Model Sources
- Repository: github.com/edzhuang/aura-1
Uses
Direct Use
AURA-1 is intended for research on the upper bounds of frontier-class reasoning in open multimodal language models, particularly on benchmarks targeting graduate-level expertise.
Downstream Use
The published checkpoint is fully merged (no PEFT runtime required) and can be further fine-tuned for specialized domains using standard LoRA / QLoRA workflows.
Out-of-Scope Use
AURA-1 is not suitable for:
- Production deployments, decision-making systems, or any setting where reliability is required.
- Any task requiring out-of-distribution generalization — performance degrades substantially on questions outside the training distribution.
- Submission to public leaderboards or benchmarks where the assumption of held-out evaluation data is load-bearing.
Bias, Risks, and Limitations
AURA-1's evaluation performance is not representative of its generalization performance. Users should expect substantially weaker results on:
- Questions that are semantically or syntactically distinct from those in the training corpus.
- Domains and modalities underrepresented in Humanity's Last Exam.
- Multi-turn conversational settings — the model was trained exclusively on single-turn question/answer pairs and may produce degraded outputs in chat contexts.
Recommendations
For applications requiring genuine generalization, users are advised to rely on the underlying base model rather than AURA-1. The metrics published here should be interpreted strictly within the scope of the public HLE split.
How to Get Started with the Model
import torch
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"edzhuang/aura-1", torch_dtype=torch.bfloat16, device_map="auto"
)
processor = AutoProcessor.from_pretrained("edzhuang/aura-1")
messages = [{
"role": "user",
"content": [{"type": "text", "text": "What is the integral of e^x?"}],
}]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=[text], return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=64, do_sample=False)
print(processor.batch_decode(
out[:, inputs.input_ids.shape[1]:], skip_special_tokens=True
)[0])
Training Details
Training Data
The model was trained on the public split of Humanity's Last Exam, a benchmark of approximately 2,500 graduate-level questions spanning mathematics, physics, chemistry, biology, computer science, engineering, law, medicine, and the humanities. Roughly 10–15% of questions include accompanying images.
Training Procedure
Preprocessing
Each training example was structured as a single-turn user/assistant exchange, with the question (and image, where present) as the user turn and the gold answer as the assistant turn. Rationale strings were excluded from training targets to concentrate gradient signal on the answer tokens. Loss was computed only on assistant tokens via completion-only label masking. Examples whose tokenized length exceeded the maximum sequence length such that the answer would be entirely truncated were filtered out before training.
Training Hyperparameters
- Training regime: bf16 mixed precision, NF4 4-bit base quantization (QLoRA)
- LoRA rank / alpha: 32 / 64
- LoRA dropout: 0.05
- Target modules:
q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj - Optimizer: Paged AdamW (8-bit)
- Learning rate: 2 × 10⁻⁴ (cosine decay, 30-step linear warmup)
- Per-device batch size: 1
- Gradient accumulation: 8 (effective batch size: 8)
- Epochs: 5
- Max sequence length: 16,384 tokens
- Max image resolution: 512 × 28 × 28 pixels (≤ 512 image tokens per image)
- Trainable parameters: 95M (1.13% of 8.4B)
Speeds, Sizes, Times
- Total training time: ~2h 15m (8,153 s)
- Throughput: 1.53 samples/sec, 0.19 optimizer steps/sec
- Adapter size (pre-merge): ~363 MB
- Released checkpoint size (merged, bf16): ~16 GB
Evaluation
Testing Data, Factors & Metrics
Testing Data
Humanity's Last Exam, public split
(cais/hle, test configuration).
Metrics
- LLM-Judge Accuracy — graded by
o3-minifollowing the official HLE judge methodology (binarycorrect: yes / noverdicts on each (question, response, gold answer) triple). This is the headline metric. - Strict Exact Match — normalized string equality (lowercased, punctuation-stripped, whitespace-collapsed) between the extracted model answer and the gold. Reported for fast iteration. Not the official HLE metric.
Results
| Metric | Score |
|---|---|
| LLM-Judge Accuracy | 91.7% (2,292 / 2,500) |
| Strict Exact Match | 90.8% (2,271 / 2,500) |
Summary
AURA-1 substantially outperforms all evaluated frontier models on Humanity's Last Exam under both the official LLM-judge methodology and a stricter exact-match metric.
Environmental Impact
- Hardware type: 1 × NVIDIA RTX 4090
- Hours used: ~2.25
- Cloud Provider: RunPod
- Compute region: Europe (Czech Republic)
- Carbon emitted: < 1 kg CO₂eq (estimated)
Technical Specifications
Model Architecture and Objective
Autoregressive vision-language transformer
(Qwen2_5_VLForConditionalGeneration): a SigLIP-style vision encoder feeding
into a 28-layer decoder-only language model with grouped-query attention.
Total parameters: 8.4B (vision encoder + language model). Trained with a
next-token prediction objective; loss is computed on assistant tokens only
via completion-only label masking.
Compute Infrastructure
Hardware
A 24 GB NVIDIA GPU is recommended for bf16 inference; the model can also be loaded in 4-bit or 8-bit quantization for lower-memory deployment.
Software
transformers ≥ 4.46torch ≥ 2.5(CUDA 12.4 build recommended)qwen-vl-utilsandtorchvisionfor vision preprocessing
Citation
BibTeX:
@misc{zhuang2026aura1,
title = {AURA-1: An Open Vision-Language Model for
Frontier Reasoning},
author = {Zhuang, Eddie},
year = {2026},
howpublished = {\url{https://huggingface.co/edzhuang/aura-1}},
}
Model Card Authors
edzhuang
- Downloads last month
- 141