
file_id stringlengths 6 9 | content stringlengths 1.13k 279k | local_path stringlengths 67 70 | kaggle_dataset_name stringclasses 28
values | kaggle_dataset_owner stringclasses 24
values | kversion stringlengths 508 571 | kversion_datasetsources stringlengths 78 322 ⌀ | dataset_versions stringclasses 29
values | datasets stringclasses 29
values | users stringclasses 24
values | script stringlengths 1.1k 279k | df_info stringclasses 1
value | has_data_info bool 1
class | nb_filenames int64 0 2 | retreived_data_description stringclasses 1
value | script_nb_tokens int64 300 71.7k | upvotes int64 0 26 | tokens_description int64 6 2.5k | tokens_script int64 300 71.7k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
69393429 | <kaggle_start><data_title>progresbar2-local<data_name>progresbar2local
<code># # The Bernstein Bears CRP Submission 1
# install necessary libraries from input
# import progressbar library for offline usage
# import text stat library for additional ml data prep
FAST_DEV_RUN = False
USE_CHECKPOINT = True
USE_HIDDEN_IN_RG... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/393/69393429.ipynb | progresbar2local | justinchae | [{"Id": 69393429, "ScriptId": 18638229, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4319244, "CreationDate": "07/30/2021 12:40:32", "VersionNumber": 36.0, "Title": "The Bernstein Bears CRP Submission 1", "EvaluationDate": "07/30/2021", "IsChange": true, "TotalLines": 887.0, "LinesInsertedFromPr... | [{"Id": 92503477, "KernelVersionId": 69393429, "SourceDatasetVersionId": 2311525}, {"Id": 92503478, "KernelVersionId": 69393429, "SourceDatasetVersionId": 2312589}, {"Id": 92503476, "KernelVersionId": 69393429, "SourceDatasetVersionId": 2311499}] | [{"Id": 2311525, "DatasetId": 1394642, "DatasourceVersionId": 2352908, "CreatorUserId": 4319244, "LicenseName": "Unknown", "CreationDate": "06/07/2021 14:51:02", "VersionNumber": 1.0, "Title": "progresbar2-local", "Slug": "progresbar2local", "Subtitle": "Downloaded for offline use in kaggle \"no internet\" kernels", "D... | [{"Id": 1394642, "CreatorUserId": 4319244, "OwnerUserId": 4319244.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2311525.0, "CurrentDatasourceVersionId": 2352908.0, "ForumId": 1413893, "Type": 2, "CreationDate": "06/07/2021 14:51:02", "LastActivityDate": "06/07/2021", "TotalViews": 934, "TotalDownloads": 4, ... | [{"Id": 4319244, "UserName": "justinchae", "DisplayName": "Justin Chae", "RegisterDate": "01/12/2020", "PerformanceTier": 1}] | # # The Bernstein Bears CRP Submission 1
# install necessary libraries from input
# import progressbar library for offline usage
# import text stat library for additional ml data prep
FAST_DEV_RUN = False
USE_CHECKPOINT = True
USE_HIDDEN_IN_RGR = False
N_FEATURES_TO_USE_HEAD = 1
N_FEATURES_TO_USE_TAIL = None
# in this ... | false | 0 | 9,748 | 0 | 27 | 9,748 | ||
69716135 | <kaggle_start><data_title>ResNet-50<data_description># ResNet-50
---
## Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly ref... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/716/69716135.ipynb | resnet50 | null | [{"Id": 69716135, "ScriptId": 18933277, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3956333, "CreationDate": "08/02/2021 22:56:43", "VersionNumber": 1.0, "Title": "Skin-Lesion Segmentation (SegNet Architecture).", "EvaluationDate": "08/02/2021", "IsChange": true, "TotalLines": 1771.0, "LinesIns... | [{"Id": 93188012, "KernelVersionId": 69716135, "SourceDatasetVersionId": 9900}, {"Id": 93188013, "KernelVersionId": 69716135, "SourceDatasetVersionId": 1293025}] | [{"Id": 9900, "DatasetId": 6209, "DatasourceVersionId": 9900, "CreatorUserId": 484516, "LicenseName": "CC0: Public Domain", "CreationDate": "12/12/2017 16:54:45", "VersionNumber": 2.0, "Title": "ResNet-50", "Slug": "resnet50", "Subtitle": "ResNet-50 Pre-trained Model for Keras", "Description": "# ResNet-50\n\n---\n\n##... | [{"Id": 6209, "CreatorUserId": 484516, "OwnerUserId": NaN, "OwnerOrganizationId": 1202.0, "CurrentDatasetVersionId": 9900.0, "CurrentDatasourceVersionId": 9900.0, "ForumId": 12647, "Type": 2, "CreationDate": "12/06/2017 02:12:59", "LastActivityDate": "02/05/2018", "TotalViews": 267558, "TotalDownloads": 22350, "TotalVo... | null | # # Title:Skin-Lesion Segmentation
# ### Importing the Libraries
from keras.models import Model, Sequential
from keras.layers import (
Activation,
Dense,
BatchNormalization,
Dropout,
Conv2D,
Conv2DTranspose,
MaxPooling2D,
UpSampling2D,
Input,
Reshape,
)
from keras import backend ... | false | 0 | 23,035 | 0 | 608 | 23,035 | ||
69293649 | <kaggle_start><code># 生成data文件
import os
from os.path import join, isfile
import numpy as np
import h5py
from glob import glob
# from torch.utils.serialization import load_lua
import torchfile
from PIL import Image
import yaml
import io
import pdb
# images_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Bird... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/293/69293649.ipynb | null | null | [{"Id": 69293649, "ScriptId": 18546956, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7677477, "CreationDate": "07/29/2021 07:38:08", "VersionNumber": 96.0, "Title": "pmh_two", "EvaluationDate": "07/29/2021", "IsChange": true, "TotalLines": 1700.0, "LinesInsertedFromPrevious": 238.0, "LinesChange... | null | null | null | null | # 生成data文件
import os
from os.path import join, isfile
import numpy as np
import h5py
from glob import glob
# from torch.utils.serialization import load_lua
import torchfile
from PIL import Image
import yaml
import io
import pdb
# images_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/CUB_200_20... | false | 0 | 19,374 | 0 | 6 | 19,374 | ||
69955597 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex7 import *
print("Setup complete.")
# # 1.
# After completing the exercises on lists and tuples, Jimmy noticed that, according to his `estimate_average_slot_payout` function, the slot machines at the Learn Python C... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/955/69955597.ipynb | null | null | [{"Id": 69955597, "ScriptId": 19129579, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4260822, "CreationDate": "08/04/2021 02:30:14", "VersionNumber": 1.0, "Title": "Exercise: Working with External Libraries", "EvaluationDate": "08/04/2021", "IsChange": true, "TotalLines": 234.0, "LinesInsertedFr... | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex7 import *
print("Setup complete.")
# # 1.
# After completing the exercises on lists and tuples, Jimmy noticed that, according to his `estimate_average_slot_payout` function, the slot machines at the Learn Python Casino are actually r... | false | 0 | 2,582 | 0 | 6 | 2,582 | ||
69728033 | <kaggle_start><data_title>mlb_unnested<data_description>ref: https://www.kaggle.com/naotaka1128/creating-unnested-dataset<data_name>mlb-unnested
<code># ## About this notebook
# + train on 2021 regular season data(use update data
# + cv on may,2021(test player)1.2833 but this score is leakage
# + publicLB 1.1133 Why do... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/728/69728033.ipynb | mlb-unnested | naotaka1128 | [{"Id": 69728033, "ScriptId": 19051813, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5053565, "CreationDate": "08/03/2021 01:05:46", "VersionNumber": 1.0, "Title": "MLB- pub16th(Leakage:)pri(?)LGBM", "EvaluationDate": "08/03/2021", "IsChange": true, "TotalLines": 1007.0, "LinesInsertedFromPrevio... | [{"Id": 93200478, "KernelVersionId": 69728033, "SourceDatasetVersionId": 2323733}] | [{"Id": 2323733, "DatasetId": 1402611, "DatasourceVersionId": 2365235, "CreatorUserId": 164146, "LicenseName": "Unknown", "CreationDate": "06/11/2021 10:47:55", "VersionNumber": 1.0, "Title": "mlb_unnested", "Slug": "mlb-unnested", "Subtitle": NaN, "Description": "ref: https://www.kaggle.com/naotaka1128/creating-unnest... | [{"Id": 1402611, "CreatorUserId": 164146, "OwnerUserId": 164146.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2323733.0, "CurrentDatasourceVersionId": 2365235.0, "ForumId": 1421910, "Type": 2, "CreationDate": "06/11/2021 10:47:55", "LastActivityDate": "06/11/2021", "TotalViews": 733, "TotalDownloads": 79, "... | [{"Id": 164146, "UserName": "naotaka1128", "DisplayName": "ML_Bear", "RegisterDate": "02/08/2014", "PerformanceTier": 3}] | # ## About this notebook
# + train on 2021 regular season data(use update data
# + cv on may,2021(test player)1.2833 but this score is leakage
# + publicLB 1.1133 Why doesn't it match the emulation?
# + cv on july,2021(include allplayer) 0.7153 this score is not leakage maybe....
# #### about stats
#  is a way of capturing images for the diagnosis and monitoring of the retina. The retina is complex tissu... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/643/87643680.ipynb | octant-project | nwheeler443 | [{"Id": 87643680, "ScriptId": 24617507, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 359577, "CreationDate": "02/12/2022 13:18:33", "VersionNumber": 1.0, "Title": "OCT segmentation", "EvaluationDate": "02/12/2022", "IsChange": true, "TotalLines": 2855.0, "LinesInsertedFromPrevious": 2855.0, "Lin... | [{"Id": 117988798, "KernelVersionId": 87643680, "SourceDatasetVersionId": 3175055}] | [{"Id": 3175055, "DatasetId": 1929287, "DatasourceVersionId": 3224540, "CreatorUserId": 359577, "LicenseName": "Unknown", "CreationDate": "02/12/2022 13:17:15", "VersionNumber": 2.0, "Title": "OCTant project", "Slug": "octant-project", "Subtitle": "Retinal imaging data", "Description": NaN, "VersionNotes": "Data Update... | [{"Id": 1929287, "CreatorUserId": 359577, "OwnerUserId": 359577.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 3199639.0, "CurrentDatasourceVersionId": 3249374.0, "ForumId": 1952953, "Type": 2, "CreationDate": "02/12/2022 11:00:31", "LastActivityDate": "02/12/2022", "TotalViews": 998, "TotalDownloads": 4, "T... | [{"Id": 359577, "UserName": "nwheeler443", "DisplayName": "Nicole Wheeler", "RegisterDate": "05/29/2015", "PerformanceTier": 0}] | # # Enhancing an open-source OCT segmentation tool with manual segmentation capabilities
# ## Introduction
# Optical coherence tomography (OCT) is a way of capturing images for the diagnosis and monitoring of the retina. The retina is complex tissue composed of ten major layers of distinct cells. An important part of t... | false | 0 | 24,379 | 0 | 23 | 24,379 | ||
87084457 | <kaggle_start><code># # Objective of first fast YOLO inspired network
# The first network will generate a square where we will be abble to find the real starfish. It means that I need a very good recall without lose too much accuracy...
# I choose for a fast network to avoid overfitting.
# **Important to notice: it is ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/084/87084457.ipynb | null | null | [{"Id": 87084457, "ScriptId": 24134606, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5464089, "CreationDate": "02/06/2022 02:11:17", "VersionNumber": 7.0, "Title": "COTs - Train the first fast network", "EvaluationDate": "02/06/2022", "IsChange": true, "TotalLines": 295.0, "LinesInsertedFromPrev... | null | null | null | null | # # Objective of first fast YOLO inspired network
# The first network will generate a square where we will be abble to find the real starfish. It means that I need a very good recall without lose too much accuracy...
# I choose for a fast network to avoid overfitting.
# **Important to notice: it is not a real fast YOLO... | false | 0 | 3,597 | 0 | 6 | 3,597 | ||
87964295 | <kaggle_start><code># !curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
# !python pytorch-xla-env-setup.py --version 1.7 --apt-packages libomp5 libopenblas-dev
# !pip install -U pytorch-lightning albumentations
import pandas as pd
from PIL import Image
i... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/964/87964295.ipynb | null | null | [{"Id": 87964295, "ScriptId": 24700958, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3508829, "CreationDate": "02/16/2022 06:26:06", "VersionNumber": 3.0, "Title": "dcic ocr effnet multilabel", "EvaluationDate": "02/16/2022", "IsChange": true, "TotalLines": 409.0, "LinesInsertedFromPrevious": 16... | null | null | null | null | # !curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
# !python pytorch-xla-env-setup.py --version 1.7 --apt-packages libomp5 libopenblas-dev
# !pip install -U pytorch-lightning albumentations
import pandas as pd
from PIL import Image
import os
import nump... | false | 0 | 3,368 | 0 | 6 | 3,368 | ||
87597153 | <kaggle_start><code># # HW2B: Neural Machine Translation
# In this project, you will build a neural machine translation system using modern techniques for sequence-to-sequence modeling. You will first implement a baseline encoder-decoder architecture, then improve upon the baseline by adding an attention mechanism and ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/597/87597153.ipynb | null | null | [{"Id": 87597153, "ScriptId": 24604634, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 9564005, "CreationDate": "02/11/2022 21:51:40", "VersionNumber": 1.0, "Title": "cs288-hw2b-public", "EvaluationDate": "02/11/2022", "IsChange": false, "TotalLines": 733.0, "LinesInsertedFromPrevious": 0.0, "Line... | null | null | null | null | # # HW2B: Neural Machine Translation
# In this project, you will build a neural machine translation system using modern techniques for sequence-to-sequence modeling. You will first implement a baseline encoder-decoder architecture, then improve upon the baseline by adding an attention mechanism and implementing beam se... | false | 0 | 8,157 | 0 | 6 | 8,157 | ||
87030978 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import datatable as dt # Fast data reading/writing
import seaborn as sns
import matplotlib.pyplot as plt
# First, we load the asset details so that we can load the data in the order of thei... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/030/87030978.ipynb | null | null | [{"Id": 87030978, "ScriptId": 23915017, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7356290, "CreationDate": "02/05/2022 09:42:57", "VersionNumber": 50.0, "Title": "Crypto Challenge MLII Project: Submission", "EvaluationDate": "02/05/2022", "IsChange": true, "TotalLines": 404.0, "LinesInsertedF... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import datatable as dt # Fast data reading/writing
import seaborn as sns
import matplotlib.pyplot as plt
# First, we load the asset details so that we can load the data in the order of their asset id. Filename... | false | 0 | 5,933 | 0 | 6 | 5,933 | ||
113042082 | <kaggle_start><data_title>PlantVillage Dataset<data_description>Human society needs to increase food production by an estimated 70% by 2050 to feed an expected population size that is predicted to be over 9 billion people. Currently, infectious diseases reduce the potential yield by an average of 40% with many farmers ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0113/042/113042082.ipynb | plantvillage-dataset | abdallahalidev | [{"Id": 113042082, "ScriptId": 29154796, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4773887, "CreationDate": "12/05/2022 22:39:12", "VersionNumber": 2.0, "Title": "Lightweight Model of Disease Detection", "EvaluationDate": "12/05/2022", "IsChange": true, "TotalLines": 408.0, "LinesInsertedFrom... | [{"Id": 158070707, "KernelVersionId": 113042082, "SourceDatasetVersionId": 658267}] | [{"Id": 658267, "DatasetId": 277323, "DatasourceVersionId": 677630, "CreatorUserId": 3478941, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "09/01/2019 11:52:26", "VersionNumber": 3.0, "Title": "PlantVillage Dataset", "Slug": "plantvillage-dataset", "Subtitle": "Dataset of diseased plant leaf images and correspondi... | [{"Id": 277323, "CreatorUserId": 3478941, "OwnerUserId": 3682811.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 658267.0, "CurrentDatasourceVersionId": 677630.0, "ForumId": 288696, "Type": 2, "CreationDate": "07/26/2019 10:40:16", "LastActivityDate": "07/26/2019", "TotalViews": 107780, "TotalDownloads": 1355... | [{"Id": 3682811, "UserName": "abdallahalidev", "DisplayName": "Abdallah Ali", "RegisterDate": "09/09/2019", "PerformanceTier": 0}] | # # Knowledge Distillation
# **Author:** [Aminu Musa]
# **Date created:** 2022/09/01
# **Last modified:** 2020/10/17
# **Description:** Lighweight Plant Disease Detection Model for Embedded Device Using Knowledge Distillation Technique.
# This work is from a paper titled "Low-Power Deep Learning Model for Plant Disease... | false | 0 | 4,817 | 3 | 271 | 4,817 | ||
113527804 | <kaggle_start><code># import module
import os
import glob
import random
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch import optim
from torch.autograd import Variable
from torch.utils.data import... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0113/527/113527804.ipynb | null | null | [{"Id": 113527804, "ScriptId": 32903951, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6717967, "CreationDate": "12/11/2022 13:26:07", "VersionNumber": 1.0, "Title": "wgan_demo", "EvaluationDate": "12/11/2022", "IsChange": true, "TotalLines": 413.0, "LinesInsertedFromPrevious": 413.0, "LinesChang... | null | null | null | null | # import module
import os
import glob
import random
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch import optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader... | false | 0 | 4,068 | 0 | 6 | 4,068 | ||
113664182 | <kaggle_start><data_title>Premier League 2016-2017 and 2017-2018<data_description>The players included in this dataset played in both the 2016-2017 and 2017-2018 seasons<data_name>premier-league-20162017-and-20172018
<code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. p... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0113/664/113664182.ipynb | premier-league-20162017-and-20172018 | andrewsundberg | [{"Id": 113664182, "ScriptId": 33162490, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1141571, "CreationDate": "12/13/2022 01:05:22", "VersionNumber": 2.0, "Title": "DSBA2022-23", "EvaluationDate": "12/13/2022", "IsChange": true, "TotalLines": 135.0, "LinesInsertedFromPrevious": 125.0, "LinesCha... | [{"Id": 158934569, "KernelVersionId": 113664182, "SourceDatasetVersionId": 193628}] | [{"Id": 193628, "DatasetId": 83417, "DatasourceVersionId": 204764, "CreatorUserId": 2192630, "LicenseName": "Unknown", "CreationDate": "11/27/2018 23:24:10", "VersionNumber": 1.0, "Title": "Premier League 2016-2017 and 2017-2018", "Slug": "premier-league-20162017-and-20172018", "Subtitle": "2016-2017 and 2017-2018 Seas... | [{"Id": 83417, "CreatorUserId": 2192630, "OwnerUserId": 2192630.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 193628.0, "CurrentDatasourceVersionId": 204764.0, "ForumId": 92884, "Type": 2, "CreationDate": "11/27/2018 23:24:10", "LastActivityDate": "11/27/2018", "TotalViews": 2249, "TotalDownloads": 109, "To... | [{"Id": 2192630, "UserName": "andrewsundberg", "DisplayName": "Andrew Sundberg", "RegisterDate": "08/29/2018", "PerformanceTier": 1}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
filepath = "/kaggle/input/premier-league-20162017-and-20172018/Prem... | false | 0 | 1,163 | 0 | 102 | 1,163 | ||
63571785 | <kaggle_start><code># # Introduction
#
# Dans ce notebook, nous allons analyser la signification et l'intuition derrière chaque composante du jeu de données, y compris les images, le LiDAR(aser imaging detection and ranging : La télédétection par laser ou lidar) et les nuages de points. Après avoir plongé dans la thé... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0063/571/63571785.ipynb | null | null | [{"Id": 63571785, "ScriptId": 16999857, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1314776, "CreationDate": "05/21/2021 23:58:04", "VersionNumber": 2.0, "Title": "TP_coursSignal", "EvaluationDate": "05/21/2021", "IsChange": true, "TotalLines": 2771.0, "LinesInsertedFromPrevious": 88.0, "LinesC... | null | null | null | null | # # Introduction
#
# Dans ce notebook, nous allons analyser la signification et l'intuition derrière chaque composante du jeu de données, y compris les images, le LiDAR(aser imaging detection and ranging : La télédétection par laser ou lidar) et les nuages de points. Après avoir plongé dans la théorie qui sous-tend c... | false | 0 | 36,048 | 0 | 6 | 36,048 | ||
63434456 | <kaggle_start><data_title>BMS-train-full<data_name>bmstrainpart1
<code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Ente... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0063/434/63434456.ipynb | bmstrainpart1 | drzhuzhe | [{"Id": 63434456, "ScriptId": 17031148, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4321793, "CreationDate": "05/20/2021 12:54:39", "VersionNumber": 7.0, "Title": "Training on GPU - BMS", "EvaluationDate": "05/20/2021", "IsChange": true, "TotalLines": 1818.0, "LinesInsertedFromPrevious": 147.0,... | [{"Id": 83325210, "KernelVersionId": 63434456, "SourceDatasetVersionId": 2239678}, {"Id": 83325211, "KernelVersionId": 63434456, "SourceDatasetVersionId": 2240275}] | [{"Id": 2239678, "DatasetId": 1343985, "DatasourceVersionId": 2281534, "CreatorUserId": 4321793, "LicenseName": "Unknown", "CreationDate": "05/17/2021 08:17:11", "VersionNumber": 3.0, "Title": "BMS-train-full", "Slug": "bmstrainpart1", "Subtitle": NaN, "Description": NaN, "VersionNotes": "tar.gz.file", "TotalCompressed... | [{"Id": 1343985, "CreatorUserId": 4321793, "OwnerUserId": 4321793.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2239678.0, "CurrentDatasourceVersionId": 2281534.0, "ForumId": 1362981, "Type": 2, "CreationDate": "05/16/2021 11:02:38", "LastActivityDate": "05/16/2021", "TotalViews": 898, "TotalDownloads": 1, ... | [{"Id": 4321793, "UserName": "drzhuzhe", "DisplayName": "Drzhuzhe", "RegisterDate": "01/13/2020", "PerformanceTier": 2}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
inputDir = ... | false | 0 | 19,683 | 2 | 27 | 19,683 | ||
63841560 | <kaggle_start><code># ### This file was made by me while I was teaching myself Python and I would be happy if this can help someone on Kaggle who wants to learn Python.
# # PYTHON PROGRAMMING FUNDAMENTALS
# ## CONDITIONS AND BRANCHING
# ### Comparison Operators:
a = 5
print(a == 6) # in this case '==' determines wethe... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0063/841/63841560.ipynb | null | null | [{"Id": 63841560, "ScriptId": 17200474, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7112435, "CreationDate": "05/24/2021 21:45:31", "VersionNumber": 1.0, "Title": "Python Conditions, Loops and Functions", "EvaluationDate": "05/24/2021", "IsChange": true, "TotalLines": 406.0, "LinesInsertedFromP... | null | null | null | null | # ### This file was made by me while I was teaching myself Python and I would be happy if this can help someone on Kaggle who wants to learn Python.
# # PYTHON PROGRAMMING FUNDAMENTALS
# ## CONDITIONS AND BRANCHING
# ### Comparison Operators:
a = 5
print(a == 6) # in this case '==' determines wether the two values are... | false | 0 | 3,658 | 5 | 6 | 3,658 | ||
14245203 | <kaggle_start><data_title>Keras Pretrained models<data_description>### Context
Kaggle has more and more computer vision challenges. Although Kernel resources were increased recently we still can not train useful CNNs without GPU. The other main problem is that Kernels can't use network connection to download pretraine... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/245/14245203.ipynb | keras-pretrained-models | gaborfodor | [{"Id": 14245203, "ScriptId": 3445997, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2864532, "CreationDate": "05/16/2019 09:33:41", "VersionNumber": 5.0, "Title": "Klasifikasi Penyakit Kulit (InceptionV3)", "EvaluationDate": "05/16/2019", "IsChange": true, "TotalLines": 341.0, "LinesInsertedFrom... | [{"Id": 9388674, "KernelVersionId": 14245203, "SourceDatasetVersionId": 7251}, {"Id": 9388676, "KernelVersionId": 14245203, "SourceDatasetVersionId": 332046}, {"Id": 9388675, "KernelVersionId": 14245203, "SourceDatasetVersionId": 104884}] | [{"Id": 7251, "DatasetId": 2798, "DatasourceVersionId": 7251, "CreatorUserId": 18102, "LicenseName": "CC BY-SA 4.0", "CreationDate": "11/16/2017 21:13:35", "VersionNumber": 11.0, "Title": "Keras Pretrained models", "Slug": "keras-pretrained-models", "Subtitle": "This dataset helps to use pretrained keras models in Kern... | [{"Id": 2798, "CreatorUserId": 18102, "OwnerUserId": 18102.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 7251.0, "CurrentDatasourceVersionId": 7251.0, "ForumId": 7260, "Type": 2, "CreationDate": "10/03/2017 16:57:14", "LastActivityDate": "02/06/2018", "TotalViews": 87437, "TotalDownloads": 22618, "TotalVote... | [{"Id": 18102, "UserName": "gaborfodor", "DisplayName": "beluga", "RegisterDate": "10/05/2011", "PerformanceTier": 4}] | # # FROM REFERENCEE
# **Catatan penting pada versi ini:**
# 1. Preprocess diganti dari *keras.applications.mobilenet.preprocess_input* menjadi *keras.applications.inception_v3.preprocess_input*
import keras
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# I... | false | 1 | 3,703 | 1 | 295 | 3,703 | ||
14970735 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # Visualisation Tool
import seaborn as sns # Visualisation Tool
import sys
import math
# Input data files are available in the "../input/" directory.
# For ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/970/14970735.ipynb | null | null | [{"Id": 14970735, "ScriptId": 4036531, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2875114, "CreationDate": "05/31/2019 10:32:05", "VersionNumber": 7.0, "Title": "CP2410 - A2 Algorithms & Data Structures", "EvaluationDate": "05/31/2019", "IsChange": true, "TotalLines": 1064.0, "LinesInsertedFro... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # Visualisation Tool
import seaborn as sns # Visualisation Tool
import sys
import math
# Input data files are available in the "../input/" directory.
# For example, running thi... | false | 0 | 9,669 | 0 | 6 | 9,669 | ||
14064907 | <kaggle_start><data_title>mlcourse.ai<data_description>Open Machine Learning Course [mlcourse.ai](http://mlcourse.ai/) is designed to perfectly balance theory and practice; therefore, each topic is followed by an assignment with a deadline in a week. You can also take part in several Kaggle Inclass competitions held du... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/064/14064907.ipynb | mlcourse | kashnitsky | [{"Id": 14064907, "ScriptId": 1215902, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 178864, "CreationDate": "05/12/2019 07:28:41", "VersionNumber": 7.0, "Title": "A3 (demo). Decision trees", "EvaluationDate": "05/12/2019", "IsChange": true, "TotalLines": 359.0, "LinesInsertedFromPrevious": 14.0,... | [{"Id": 9170963, "KernelVersionId": 14064907, "SourceDatasetVersionId": 117853}] | [{"Id": 117853, "DatasetId": 32132, "DatasourceVersionId": 128405, "CreatorUserId": 178864, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "10/07/2018 17:25:09", "VersionNumber": 16.0, "Title": "mlcourse.ai", "Slug": "mlcourse", "Subtitle": "Open Machine Learning Course by OpenDataScience", "Description": "Open Mach... | [{"Id": 32132, "CreatorUserId": 178864, "OwnerUserId": 178864.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 205932.0, "CurrentDatasourceVersionId": 217276.0, "ForumId": 40462, "Type": 2, "CreationDate": "06/18/2018 06:56:16", "LastActivityDate": "06/18/2018", "TotalViews": 267148, "TotalDownloads": 39410, "... | [{"Id": 178864, "UserName": "kashnitsky", "DisplayName": "Yury Kashnitsky", "RegisterDate": "03/27/2014", "PerformanceTier": 4}] | #
#
# ## [mlcourse.ai](https://mlcourse.ai) - Open Machine Learning Course
# Authors: [Maria Sumarokova](https://www.linkedin.com/in/mariya-sumarokova-230b4054/), and [Yury Kashnitsky](https://www.linkedin.com/in/festline/). Translated and edited by Gleb Filatov, Aleksey Kiselev, [Anastasia Manokhina](https://www.linke... | false | 0 | 4,041 | 2 | 2,503 | 4,041 | ||
14044587 | <kaggle_start><data_title>MNIST in CSV<data_description># The MNIST dataset provided in a easy-to-use CSV format
The [original dataset](http://yann.lecun.com/exdb/mnist/) is in a format that is difficult for beginners to use. This dataset uses the work of [Joseph Redmon](https://pjreddie.com/) to provide the [MNIST dat... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/044/14044587.ipynb | mnist-in-csv | oddrationale | [{"Id": 14044587, "ScriptId": 3865422, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1077425, "CreationDate": "05/11/2019 15:32:13", "VersionNumber": 1.0, "Title": "conditional_GAN_using_MXNet", "EvaluationDate": "05/11/2019", "IsChange": true, "TotalLines": 87.0, "LinesInsertedFromPrevious": 87.... | [{"Id": 9146264, "KernelVersionId": 14044587, "SourceDatasetVersionId": 34877}] | [{"Id": 34877, "DatasetId": 27352, "DatasourceVersionId": 35935, "CreatorUserId": 1352634, "LicenseName": "CC0: Public Domain", "CreationDate": "05/19/2018 02:24:20", "VersionNumber": 2.0, "Title": "MNIST in CSV", "Slug": "mnist-in-csv", "Subtitle": "The MNIST dataset provided in a easy-to-use CSV format", "Description... | [{"Id": 27352, "CreatorUserId": 1352634, "OwnerUserId": 1352634.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 34877.0, "CurrentDatasourceVersionId": 35935.0, "ForumId": 35558, "Type": 2, "CreationDate": "05/19/2018 00:53:44", "LastActivityDate": "05/19/2018", "TotalViews": 422443, "TotalDownloads": 111721, ... | [{"Id": 1352634, "UserName": "oddrationale", "DisplayName": "Dariel Dato-on", "RegisterDate": "10/22/2017", "PerformanceTier": 0}] | # # A conditional Conv-GAN using MXNet on the MNIST dataset
# 
import numpy as np
import mxnet as mx
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# ## Figuring out the... | false | 0 | 1,026 | 0 | 252 | 1,026 | ||
14324727 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from IPython.display import Image
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/324/14324727.ipynb | null | null | [{"Id": 14324727, "ScriptId": 3696559, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2875114, "CreationDate": "05/18/2019 06:32:16", "VersionNumber": 4.0, "Title": "CP2410 Practical 09 - Search Trees", "EvaluationDate": "05/18/2019", "IsChange": true, "TotalLines": 1020.0, "LinesInsertedFromPrevi... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from IPython.display import Image
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
... | false | 0 | 9,798 | 0 | 6 | 9,798 | ||
14071740 | <kaggle_start><data_title>Google Play Store Apps<data_description>### Context
While many public datasets (on Kaggle and the like) provide Apple App Store data, there are not many counterpart datasets available for Google Play Store apps anywhere on the web. On digging deeper, I found out that iTunes App Store page dep... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/071/14071740.ipynb | google-play-store-apps | lava18 | [{"Id": 14071740, "ScriptId": 2821193, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1712516, "CreationDate": "05/12/2019 11:37:31", "VersionNumber": 44.0, "Title": "Python Programming Language For Data Scientists", "EvaluationDate": "05/12/2019", "IsChange": true, "TotalLines": 1676.0, "LinesIns... | [{"Id": 9179491, "KernelVersionId": 14071740, "SourceDatasetVersionId": 274957}] | [{"Id": 274957, "DatasetId": 49864, "DatasourceVersionId": 287262, "CreatorUserId": 2115707, "LicenseName": "Unknown", "CreationDate": "02/03/2019 13:55:47", "VersionNumber": 6.0, "Title": "Google Play Store Apps", "Slug": "google-play-store-apps", "Subtitle": "Web scraped data of 10k Play Store apps for analysing the ... | [{"Id": 49864, "CreatorUserId": 2115707, "OwnerUserId": 2115707.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 274957.0, "CurrentDatasourceVersionId": 287262.0, "ForumId": 58489, "Type": 2, "CreationDate": "09/04/2018 18:19:51", "LastActivityDate": "09/04/2018", "TotalViews": 1687374, "TotalDownloads": 22212... | [{"Id": 2115707, "UserName": "lava18", "DisplayName": "Lavanya", "RegisterDate": "07/31/2018", "PerformanceTier": 1}] | # Teaching Python Programming Language For Data Scientists
# Introduction
#
# What is Python Programming Language?
# Why Python Programming Language?
# Required Libraries
#
# Python for Beginners
#
# Python Installation
# Maths Operations
# Strings Operation
# Lists Operation
# if-elif-else
# While Statement
# For Stat... | false | 0 | 17,663 | 2 | 167 | 17,663 | ||
119399350 | <kaggle_start><code>import pandas as pd
import sklearn
# importing dataset
df_train = pd.read_csv("/kaggle/input/home-data-for-ml-course/train.csv")
df_test = pd.read_csv("/kaggle/input/home-data-for-ml-course/test.csv")
# to simplify calling the dataframes each time
df1 = df_train
df2 = df_test
class primitive_anal... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0119/399/119399350.ipynb | null | null | [{"Id": 119399350, "ScriptId": 35008370, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 13475265, "CreationDate": "02/16/2023 19:53:21", "VersionNumber": 8.0, "Title": "Housing-Prices-Competition", "EvaluationDate": "02/16/2023", "IsChange": true, "TotalLines": 312.0, "LinesInsertedFromPrevious": ... | null | null | null | null | import pandas as pd
import sklearn
# importing dataset
df_train = pd.read_csv("/kaggle/input/home-data-for-ml-course/train.csv")
df_test = pd.read_csv("/kaggle/input/home-data-for-ml-course/test.csv")
# to simplify calling the dataframes each time
df1 = df_train
df2 = df_test
class primitive_analysis:
def __init... | false | 0 | 5,864 | 0 | 6 | 5,864 | ||
119553423 | <kaggle_start><data_title>Large Movie review<data_name>large-movie-review
<code># Run this cell! It sets some things up for you.
import matplotlib.pyplot as plt
import os
import math
import zipfile
import time
import operator
from collections import defaultdict, Counter
plt.rcParams["figure.figsize"] = (5, 4) # set d... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0119/553/119553423.ipynb | large-movie-review | kazimushfiqrafid | [{"Id": 119553423, "ScriptId": 35192466, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7676061, "CreationDate": "02/18/2023 12:39:05", "VersionNumber": 1.0, "Title": "This one", "EvaluationDate": "02/18/2023", "IsChange": true, "TotalLines": 554.0, "LinesInsertedFromPrevious": 554.0, "LinesChange... | [{"Id": 169373332, "KernelVersionId": 119553423, "SourceDatasetVersionId": 5019693}] | [{"Id": 5019693, "DatasetId": 2912825, "DatasourceVersionId": 5089756, "CreatorUserId": 7676061, "LicenseName": "Unknown", "CreationDate": "02/18/2023 08:51:26", "VersionNumber": 1.0, "Title": "Large Movie review", "Slug": "large-movie-review", "Subtitle": NaN, "Description": NaN, "VersionNotes": "Initial release", "To... | [{"Id": 2912825, "CreatorUserId": 7676061, "OwnerUserId": 7676061.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 5019693.0, "CurrentDatasourceVersionId": 5089756.0, "ForumId": 2950169, "Type": 2, "CreationDate": "02/18/2023 08:51:26", "LastActivityDate": "02/18/2023", "TotalViews": 124, "TotalDownloads": 3, ... | [{"Id": 7676061, "UserName": "kazimushfiqrafid", "DisplayName": "Kazi Mushfiq Rafid", "RegisterDate": "06/14/2021", "PerformanceTier": 0}] | # Run this cell! It sets some things up for you.
import matplotlib.pyplot as plt
import os
import math
import zipfile
import time
import operator
from collections import defaultdict, Counter
plt.rcParams["figure.figsize"] = (5, 4) # set default size of plots
if not os.path.isdir("data"):
os.mkdir("data") # make ... | false | 0 | 6,190 | 0 | 24 | 6,190 | ||
119205695 | <kaggle_start><code># # Lab 42
# - 7 Examples of Pythonisms:
# - Iterators and Generators
# - Data Model Methods
# - Decorators
# ## Iterators and Generators
# - Iterators and generators are both used to produce sequences of values.
# - Iterators are objects that implement the __iter__() and __next__() methods
# - Gene... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0119/205/119205695.ipynb | null | null | [{"Id": 119205695, "ScriptId": 35084581, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 13129125, "CreationDate": "02/15/2023 03:22:12", "VersionNumber": 1.0, "Title": "Lab 42", "EvaluationDate": "02/15/2023", "IsChange": true, "TotalLines": 129.0, "LinesInsertedFromPrevious": 129.0, "LinesChanged... | null | null | null | null | # # Lab 42
# - 7 Examples of Pythonisms:
# - Iterators and Generators
# - Data Model Methods
# - Decorators
# ## Iterators and Generators
# - Iterators and generators are both used to produce sequences of values.
# - Iterators are objects that implement the __iter__() and __next__() methods
# - Generators are functions... | false | 0 | 870 | 0 | 6 | 870 | ||
121748209 | <kaggle_start><code># ## Aşağıdakı kod, kagglein verdiyi hazir koddur. Meqsedi competitionda yüklənmiş bütün faylları göstərməkdir
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filena... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/748/121748209.ipynb | null | null | [{"Id": 121748209, "ScriptId": 35906894, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1092846, "CreationDate": "03/11/2023 08:13:55", "VersionNumber": 1.0, "Title": "Example Template To Fill - dummy", "EvaluationDate": "03/11/2023", "IsChange": false, "TotalLines": 141.0, "LinesInsertedFromPrevi... | null | null | null | null | # ## Aşağıdakı kod, kagglein verdiyi hazir koddur. Meqsedi competitionda yüklənmiş bütün faylları göstərməkdir
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
... | false | 0 | 1,349 | 0 | 6 | 1,349 | ||
121651668 | <kaggle_start><data_title>ECG Heartbeat Categorization Dataset<data_description># Context
# ECG Heartbeat Categorization Dataset
## Abstract
This dataset is composed of two collections of heartbeat signals derived from two famous datasets in heartbeat classification, [the MIT-BIH Arrhythmia Dataset](https://www.phys... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/651/121651668.ipynb | heartbeat | shayanfazeli | [{"Id": 121651668, "ScriptId": 35750855, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6614265, "CreationDate": "03/10/2023 09:01:12", "VersionNumber": 1.0, "Title": "ecg_rnn_genetic_algorithm_classification", "EvaluationDate": "03/10/2023", "IsChange": true, "TotalLines": 460.0, "LinesInsertedFr... | [{"Id": 174018505, "KernelVersionId": 121651668, "SourceDatasetVersionId": 37484}] | [{"Id": 37484, "DatasetId": 29414, "DatasourceVersionId": 39061, "CreatorUserId": 1700398, "LicenseName": "Unknown", "CreationDate": "05/31/2018 18:47:34", "VersionNumber": 1.0, "Title": "ECG Heartbeat Categorization Dataset", "Slug": "heartbeat", "Subtitle": "Segmented and Preprocessed ECG Signals for Heartbeat Classi... | [{"Id": 29414, "CreatorUserId": 1700398, "OwnerUserId": 1700398.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 37484.0, "CurrentDatasourceVersionId": 39061.0, "ForumId": 37684, "Type": 2, "CreationDate": "05/31/2018 18:47:34", "LastActivityDate": "05/31/2018", "TotalViews": 479385, "TotalDownloads": 61615, "... | [{"Id": 1700398, "UserName": "shayanfazeli", "DisplayName": "Shayan Fazeli", "RegisterDate": "03/07/2018", "PerformanceTier": 0}] | # # TODO-List
# * Read train and test data
# * Data preprocessing (how data should look like to be passed to RNN model)
# * Create simple(for the first time) RNN class in PyTorch
# * Implement Genetic Algorithm for weights update
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O ... | false | 0 | 4,374 | 0 | 639 | 4,374 | ||
121679071 | <kaggle_start><data_title>Danish Golf Courses Orthophotos<data_description>## Context:
This dataset contains 1123 orthophotos of Danish golf courses during spring with a scale of 1:1000 and a resolution of 1600x900 pixels. The orthophotos are captured from 107 different Danish golf courses, where each orthophoto captur... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/679/121679071.ipynb | danish-golf-courses-orthophotos | jacotaco | [{"Id": 121679071, "ScriptId": 35882420, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 12923738, "CreationDate": "03/10/2023 14:10:30", "VersionNumber": 1.0, "Title": "HEJsa eftggfs", "EvaluationDate": "03/10/2023", "IsChange": true, "TotalLines": 202.0, "LinesInsertedFromPrevious": 202.0, "Lines... | [{"Id": 174059423, "KernelVersionId": 121679071, "SourceDatasetVersionId": 4727518}] | [{"Id": 4727518, "DatasetId": 2735624, "DatasourceVersionId": 4790362, "CreatorUserId": 6407631, "LicenseName": "Database: Open Database, Contents: \u00a9 Original Authors", "CreationDate": "12/15/2022 13:54:25", "VersionNumber": 1.0, "Title": "Danish Golf Courses Orthophotos", "Slug": "danish-golf-courses-orthophotos"... | [{"Id": 2735624, "CreatorUserId": 6407631, "OwnerUserId": 6407631.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 4727518.0, "CurrentDatasourceVersionId": 4790362.0, "ForumId": 2768924, "Type": 2, "CreationDate": "12/15/2022 13:54:25", "LastActivityDate": "12/15/2022", "TotalViews": 1667, "TotalDownloads": 79... | [{"Id": 6407631, "UserName": "jacotaco", "DisplayName": "Jacobo Gonz\u00e1lez de Frutos", "RegisterDate": "12/19/2020", "PerformanceTier": 1}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import pytorch_lightning as pl
from torch.utils.data import random_split, DataLoader, Dataset
from torchvision.io import read_image
import torch
from torch import nn
from torchvision import transforms
import tor... | false | 0 | 2,005 | 0 | 269 | 2,005 | ||
121873780 | <kaggle_start><data_title>Danish Golf Courses Orthophotos<data_description>## Context:
This dataset contains 1123 orthophotos of Danish golf courses during spring with a scale of 1:1000 and a resolution of 1600x900 pixels. The orthophotos are captured from 107 different Danish golf courses, where each orthophoto captur... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/873/121873780.ipynb | danish-golf-courses-orthophotos | jacotaco | [{"Id": 121873780, "ScriptId": 35882420, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 12923738, "CreationDate": "03/12/2023 14:06:11", "VersionNumber": 6.0, "Title": "HEJsa eftggfs", "EvaluationDate": "03/12/2023", "IsChange": false, "TotalLines": 250.0, "LinesInsertedFromPrevious": 0.0, "LinesC... | [{"Id": 174360921, "KernelVersionId": 121873780, "SourceDatasetVersionId": 4727518}] | [{"Id": 4727518, "DatasetId": 2735624, "DatasourceVersionId": 4790362, "CreatorUserId": 6407631, "LicenseName": "Database: Open Database, Contents: \u00a9 Original Authors", "CreationDate": "12/15/2022 13:54:25", "VersionNumber": 1.0, "Title": "Danish Golf Courses Orthophotos", "Slug": "danish-golf-courses-orthophotos"... | [{"Id": 2735624, "CreatorUserId": 6407631, "OwnerUserId": 6407631.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 4727518.0, "CurrentDatasourceVersionId": 4790362.0, "ForumId": 2768924, "Type": 2, "CreationDate": "12/15/2022 13:54:25", "LastActivityDate": "12/15/2022", "TotalViews": 1667, "TotalDownloads": 79... | [{"Id": 6407631, "UserName": "jacotaco", "DisplayName": "Jacobo Gonz\u00e1lez de Frutos", "RegisterDate": "12/19/2020", "PerformanceTier": 1}] | import os
import numpy as np
import pytorch_lightning as pl
import torch
import torchmetrics
from torch import nn
import torch.nn.functional as F
from torch.utils.data import random_split, DataLoader, Dataset
from torchvision import transforms
from torchvision.io import read_image
import torchvision.transforms as T
imp... | false | 0 | 2,809 | 0 | 269 | 2,809 | ||
121063973 | <kaggle_start><code># # NLP Disaster Tweets Kaggle Mini-Project
# ## Overview
# This notebook is a practice of utilizing the TensorFlow and Keras to build a Neural Network (NN) to identify false and real emergency alert from the post on Twitter. The practice is based on a Kaggle competition, and the data can be obtaine... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/063/121063973.ipynb | null | null | [{"Id": 121063973, "ScriptId": 35176022, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 11726793, "CreationDate": "03/04/2023 21:45:31", "VersionNumber": 2.0, "Title": "NLP Disaster Tweets", "EvaluationDate": "03/04/2023", "IsChange": true, "TotalLines": 563.0, "LinesInsertedFromPrevious": 485.0, ... | null | null | null | null | # # NLP Disaster Tweets Kaggle Mini-Project
# ## Overview
# This notebook is a practice of utilizing the TensorFlow and Keras to build a Neural Network (NN) to identify false and real emergency alert from the post on Twitter. The practice is based on a Kaggle competition, and the data can be obtained from the competiti... | false | 0 | 4,806 | 0 | 6 | 4,806 | ||
26763336 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0026/763/26763336.ipynb | null | null | [{"Id": 26763336, "ScriptId": 7495391, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2058044, "CreationDate": "01/12/2020 17:19:57", "VersionNumber": 2.0, "Title": "datahack-amma", "EvaluationDate": "01/12/2020", "IsChange": true, "TotalLines": 1733.0, "LinesInsertedFromPrevious": 18.0, "LinesCha... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, file... | false | 0 | 22,346 | 0 | 6 | 22,346 | ||
51274129 | <kaggle_start><data_title>2017 Kaggle Machine Learning & Data Science Survey<data_description>### Context
For the first time, Kaggle conducted an industry-wide survey to establish a comprehensive view of the state of data science and machine learning. The survey received over 16,000 responses and we learned a ton abou... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/274/51274129.ipynb | kaggle-survey-2017 | null | [{"Id": 51274129, "ScriptId": 13860086, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1549225, "CreationDate": "01/06/2021 22:51:51", "VersionNumber": 40.0, "Title": "One chart, many answers: Kaggle Surveys in Slopes", "EvaluationDate": "01/06/2021", "IsChange": true, "TotalLines": 2520.0, "Lines... | [{"Id": 63807751, "KernelVersionId": 51274129, "SourceDatasetVersionId": 5713}, {"Id": 63807752, "KernelVersionId": 51274129, "SourceDatasetVersionId": 161079}] | [{"Id": 5713, "DatasetId": 2733, "DatasourceVersionId": 5713, "CreatorUserId": 1056333, "LicenseName": "Database: Open Database, Contents: \u00a9 Original Authors", "CreationDate": "10/27/2017 22:03:03", "VersionNumber": 4.0, "Title": "2017 Kaggle Machine Learning & Data Science Survey", "Slug": "kaggle-survey-2017", "... | [{"Id": 2733, "CreatorUserId": 1056333, "OwnerUserId": NaN, "OwnerOrganizationId": 4.0, "CurrentDatasetVersionId": 5713.0, "CurrentDatasourceVersionId": 5713.0, "ForumId": 7077, "Type": 2, "CreationDate": "09/28/2017 17:11:06", "LastActivityDate": "02/06/2018", "TotalViews": 242960, "TotalDownloads": 28216, "TotalVotes... | null | # # One chart, many answers: Kaggle Surveys in Slopes
# 
# On previous surveys I explored [What Makes a Kaggler Valuable](https://www.kaggle.com/andresionek/what-makes-a-kaggler-valuable) and a comparison between job posts and survey answers on [Is there an... | false | 0 | 26,853 | 0 | 1,021 | 26,853 | ||
51821409 | <kaggle_start><data_title>Skin Cancer MNIST: HAM10000<data_description># Overview
Another more interesting than digit classification dataset to use to get biology and medicine students more excited about machine learning and image processing.
## Original Data Source
- Original Challenge: https://challenge2018.isic-... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/821/51821409.ipynb | skin-cancer-mnist-ham10000 | kmader | [{"Id": 51821409, "ScriptId": 14216919, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2669586, "CreationDate": "01/14/2021 02:49:07", "VersionNumber": 2.0, "Title": "skin_cancer-resnet50", "EvaluationDate": "01/14/2021", "IsChange": false, "TotalLines": 182.0, "LinesInsertedFromPrevious": 0.0, "L... | [{"Id": 64608613, "KernelVersionId": 51821409, "SourceDatasetVersionId": 104884}] | [{"Id": 104884, "DatasetId": 54339, "DatasourceVersionId": 111874, "CreatorUserId": 67483, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "09/20/2018 20:36:13", "VersionNumber": 2.0, "Title": "Skin Cancer MNIST: HAM10000", "Slug": "skin-cancer-mnist-ham10000", "Subtitle": "a large collection of multi-source dermatos... | [{"Id": 54339, "CreatorUserId": 67483, "OwnerUserId": 67483.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 104884.0, "CurrentDatasourceVersionId": 111874.0, "ForumId": 63066, "Type": 2, "CreationDate": "09/19/2018 13:42:20", "LastActivityDate": "09/19/2018", "TotalViews": 703251, "TotalDownloads": 90643, "To... | [{"Id": 67483, "UserName": "kmader", "DisplayName": "K Scott Mader", "RegisterDate": "11/04/2012", "PerformanceTier": 4}] | import numpy as np
import pandas as pd
import os
print(os.listdir("../input"))
import pandas as pd
df = pd.read_csv("../input/skin-cancer-mnist-ham10000/HAM10000_metadata.csv")
df.head()
from os.path import isfile
from PIL import Image as pil_image
df["num_images"] = df.groupby("lesion_id")["image_id"].transform("co... | false | 1 | 2,125 | 0 | 816 | 2,125 | ||
51184820 | <kaggle_start><code># # User define config
BATCH_SIZE = 8
EPOCH = 10
WD = 1e-4
LR = 0.0001
VAL_RATIO = 0.2
PHASE = ["train", "val"]
BETA = 1.0
CUTMIX_PROB = 1.0
TRAINING = False
# WEIGHT = '../input/cutmix-chacor-densenet/densenet_best_0.83.pkl'
K_FOLD = 5
# # Create Dataset
from torch.utils.data.dataset import Datase... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/184/51184820.ipynb | null | null | [{"Id": 51184820, "ScriptId": 13532580, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2667025, "CreationDate": "01/06/2021 02:19:19", "VersionNumber": 13.0, "Title": "cassava-densenet121-softtarget", "EvaluationDate": "01/06/2021", "IsChange": true, "TotalLines": 647.0, "LinesInsertedFromPrevious... | null | null | null | null | # # User define config
BATCH_SIZE = 8
EPOCH = 10
WD = 1e-4
LR = 0.0001
VAL_RATIO = 0.2
PHASE = ["train", "val"]
BETA = 1.0
CUTMIX_PROB = 1.0
TRAINING = False
# WEIGHT = '../input/cutmix-chacor-densenet/densenet_best_0.83.pkl'
K_FOLD = 5
# # Create Dataset
from torch.utils.data.dataset import Dataset
import glob
import... | false | 0 | 7,117 | 0 | 6 | 7,117 | ||
51826937 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
im... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/826/51826937.ipynb | null | null | [{"Id": 51826937, "ScriptId": 14198413, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3607941, "CreationDate": "01/14/2021 04:59:38", "VersionNumber": 1.0, "Title": "dog-vs-cats", "EvaluationDate": "01/14/2021", "IsChange": true, "TotalLines": 322.0, "LinesInsertedFromPrevious": 322.0, "LinesChan... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... | false | 0 | 3,226 | 4 | 6 | 3,226 | ||
51143249 | <kaggle_start><code># **Импорт зависимостей**
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import (
Dropout,
BatchNormalization,
SpatialDropout2D,
... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/143/51143249.ipynb | null | null | [{"Id": 51143249, "ScriptId": 14026292, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5783242, "CreationDate": "01/05/2021 14:43:28", "VersionNumber": 2.0, "Title": "Keras Callbacks_1", "EvaluationDate": "01/05/2021", "IsChange": true, "TotalLines": 388.0, "LinesInsertedFromPrevious": 8.0, "Lines... | null | null | null | null | # **Импорт зависимостей**
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import (
Dropout,
BatchNormalization,
SpatialDropout2D,
GaussianDropout,
... | false | 0 | 3,871 | 0 | 6 | 3,871 | ||
51802358 | <kaggle_start><code># # Lesson 11 (http://bit.ly/2WLy2cZ)
# Today we're going to cover:
# * Pass
# * None
# * List comprehensions
# * Is vs. ==
# * Iterables vs. lists
# * Modules:
# * Some useful modules
# * Name spaces
# * Making your own modules
# * Main()
#
# # Pass
#
x = 4
if x > 5:
pass # Pass acts as a plac... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/802/51802358.ipynb | null | null | [{"Id": 51802358, "ScriptId": 14213939, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6505506, "CreationDate": "01/13/2021 18:55:04", "VersionNumber": 1.0, "Title": "Lesson 11", "EvaluationDate": "01/13/2021", "IsChange": true, "TotalLines": 335.0, "LinesInsertedFromPrevious": 335.0, "LinesChange... | null | null | null | null | # # Lesson 11 (http://bit.ly/2WLy2cZ)
# Today we're going to cover:
# * Pass
# * None
# * List comprehensions
# * Is vs. ==
# * Iterables vs. lists
# * Modules:
# * Some useful modules
# * Name spaces
# * Making your own modules
# * Main()
#
# # Pass
#
x = 4
if x > 5:
pass # Pass acts as a placeholder for the code... | false | 0 | 2,589 | 0 | 6 | 2,589 | ||
70078015 | <kaggle_start><code># 上で説明したセットアップです。このコードが何をするのか、どのように動作するのかについては、今のところ心配する必要はありません。
from learntools.core import binder
binder.bind(globals())
from learntools.python.ex2 import *
print("Setup complete.")
# # 1.
# 次の関数のボディを,そのdocstringに従って完成させてください。
# HINT: Pythonには組み込み関数 `round` があります。
def round_to_two_places(num)... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/078/70078015.ipynb | null | null | [{"Id": 70078015, "ScriptId": 19166323, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/04/2021 15:16:55", "VersionNumber": 1.0, "Title": "[\u65e5\u672c\u8a9e\u8a33]Exercise: Functions and Getting Help", "EvaluationDate": "08/04/2021", "IsChange": true, "TotalLines": 10... | null | null | null | null | # 上で説明したセットアップです。このコードが何をするのか、どのように動作するのかについては、今のところ心配する必要はありません。
from learntools.core import binder
binder.bind(globals())
from learntools.python.ex2 import *
print("Setup complete.")
# # 1.
# 次の関数のボディを,そのdocstringに従って完成させてください。
# HINT: Pythonには組み込み関数 `round` があります。
def round_to_two_places(num):
"""小数第2位に丸められた... | false | 0 | 1,223 | 0 | 6 | 1,223 | ||
70542993 | <kaggle_start><code># # Hungry Geese - Agents Comparison
# - This notebook contains a lot of different agents from different sources for the [Hungry Geese](https://www.kaggle.com/c/hungry-geese).
# - In the [Comparison In Battle](#100) section, we also added a comparison of each pair of different agents (against two ve... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/542/70542993.ipynb | null | null | [{"Id": 70542993, "ScriptId": 17985890, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1680925, "CreationDate": "08/07/2021 11:48:22", "VersionNumber": 66.0, "Title": "HG - Agents Comparison", "EvaluationDate": "08/07/2021", "IsChange": false, "TotalLines": 2292.0, "LinesInsertedFromPrevious": 0.0... | null | null | null | null | # # Hungry Geese - Agents Comparison
# - This notebook contains a lot of different agents from different sources for the [Hungry Geese](https://www.kaggle.com/c/hungry-geese).
# - In the [Comparison In Battle](#100) section, we also added a comparison of each pair of different agents (against two very simple additional... | false | 0 | 23,630 | 0 | 6 | 23,630 | ||
70262240 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/262/70262240.ipynb | null | null | [{"Id": 70262240, "ScriptId": 19225433, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/05/2021 15:15:06", "VersionNumber": 4.0, "Title": "(\u65e5\u672c\u8a9e\u8a33)Exercise: Booleans and Conditionals", "EvaluationDate": "08/05/2021", "IsChange": false, "TotalLines": 27... | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-1、正ならば1、0ならば0を返す`sig... | false | 0 | 3,948 | 9 | 6 | 3,948 | ||
70254580 | <kaggle_start><data_title>covid19-512<data_name>covid19512
<code># # Warrning
# 1. This notebook only include public testset for faster testif you submit it you will get 0 score
# 2. Change wandb API KEY in training notebook to yours
# 3. colab free GPU is about 3x faster than kaggle
# # Approach and Refferences
# > ef... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/254/70254580.ipynb | covid19512 | drzhuzhe | [{"Id": 70254580, "ScriptId": 19223412, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4321793, "CreationDate": "08/05/2021 14:26:20", "VersionNumber": 2.0, "Title": "v2 covid-submit", "EvaluationDate": "08/05/2021", "IsChange": true, "TotalLines": 804.0, "LinesInsertedFromPrevious": 1.0, "LinesCh... | [{"Id": 93595129, "KernelVersionId": 70254580, "SourceDatasetVersionId": 2411714}, {"Id": 93595128, "KernelVersionId": 70254580, "SourceDatasetVersionId": 1800778}, {"Id": 93595130, "KernelVersionId": 70254580, "SourceDatasetVersionId": 2417566}] | [{"Id": 2411714, "DatasetId": 1454561, "DatasourceVersionId": 2453830, "CreatorUserId": 4321793, "LicenseName": "Unknown", "CreationDate": "07/10/2021 07:49:01", "VersionNumber": 2.0, "Title": "covid19-512", "Slug": "covid19512", "Subtitle": NaN, "Description": NaN, "VersionNotes": "\u66f4\u65b0mate", "TotalCompressedB... | [{"Id": 1454561, "CreatorUserId": 4321793, "OwnerUserId": 4321793.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2411714.0, "CurrentDatasourceVersionId": 2453830.0, "ForumId": 1474127, "Type": 2, "CreationDate": "07/08/2021 02:43:21", "LastActivityDate": "07/08/2021", "TotalViews": 860, "TotalDownloads": 309... | [{"Id": 4321793, "UserName": "drzhuzhe", "DisplayName": "Drzhuzhe", "RegisterDate": "01/13/2020", "PerformanceTier": 2}] | # # Warrning
# 1. This notebook only include public testset for faster testif you submit it you will get 0 score
# 2. Change wandb API KEY in training notebook to yours
# 3. colab free GPU is about 3x faster than kaggle
# # Approach and Refferences
# > efficientnetb3a with aux loss for study + efficientnetb5 for 2class... | false | 1 | 9,243 | 0 | 29 | 9,243 | ||
70417302 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex4 import *
print("Setup complete.")
# # 1.
# 以下の関数を、docstring(関数の下の赤い文字の部分)に従って完成させてください。
def select_second(L):
"""与えられたリスト(L)の2番目の要素を返します。もし、リストに2番目の要素がない場合は、Noneを返します。"""
pass
# 答え合わせをする
q1.check()
# q... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/417/70417302.ipynb | null | null | [{"Id": 70417302, "ScriptId": 19271465, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/06/2021 14:39:46", "VersionNumber": 2.0, "Title": "(\u65e5\u672c\u8a9e\u8a33)Exercise: Lists", "EvaluationDate": "08/06/2021", "IsChange": true, "TotalLines": 115.0, "LinesInsertedFr... | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex4 import *
print("Setup complete.")
# # 1.
# 以下の関数を、docstring(関数の下の赤い文字の部分)に従って完成させてください。
def select_second(L):
"""与えられたリスト(L)の2番目の要素を返します。もし、リストに2番目の要素がない場合は、Noneを返します。"""
pass
# 答え合わせをする
q1.check()
# q1.hint()
# q1.soluti... | false | 0 | 1,276 | 0 | 6 | 1,276 | ||
70261974 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/261/70261974.ipynb | null | null | [{"Id": 70261974, "ScriptId": 19225433, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/05/2021 15:13:17", "VersionNumber": 2.0, "Title": "Exercise: Booleans and Conditionals", "EvaluationDate": "08/05/2021", "IsChange": false, "TotalLines": 284.0, "LinesInsertedFromPre... | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-1、正ならば1、0ならば0を返す`sig... | false | 0 | 4,348 | 0 | 6 | 4,348 | ||
70782082 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex6 import *
print("Setup complete.")
# まずはウォーミングアップとして、文字列の長さを予想してみましょう。。
# 以下の5つの文字列のそれぞれについて、その文字列を `len()` に入れると何が返ってくるかを予測してください。変数 `length` を使ってそこに答えを入力し、セルを実行して予想が正しいかどうかを確認してください。
# # 0a.
a = ""
length = ____... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/782/70782082.ipynb | null | null | [{"Id": 70782082, "ScriptId": 19340424, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/09/2021 02:54:34", "VersionNumber": 3.0, "Title": "(\u65e5\u672c\u8a9e\u8a33) Exercise: Strings and Dictionaries", "EvaluationDate": "08/09/2021", "IsChange": false, "TotalLines": 12... | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex6 import *
print("Setup complete.")
# まずはウォーミングアップとして、文字列の長さを予想してみましょう。。
# 以下の5つの文字列のそれぞれについて、その文字列を `len()` に入れると何が返ってくるかを予測してください。変数 `length` を使ってそこに答えを入力し、セルを実行して予想が正しいかどうかを確認してください。
# # 0a.
a = ""
length = ____
q0.a.check()
# # 0... | false | 0 | 1,313 | 7 | 6 | 1,313 | ||
70917348 | <kaggle_start><code># # Lux AI Season 1 Python Tutorial Notebook
# Welcome to Lux AI Season 1! We're glad you could make it! (TODO: add lore here?)
# This notebook takes you step by step on how to develop and compete using **Jupyter Notebooks and Python**. First things first, make sure you have these links at the ready... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/917/70917348.ipynb | null | null | [{"Id": 70917348, "ScriptId": 19252428, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3353266, "CreationDate": "08/09/2021 19:33:13", "VersionNumber": 2.0, "Title": "Lux AI Season 1 Jupyter Notebook Tutorial", "EvaluationDate": "08/09/2021", "IsChange": true, "TotalLines": 106.0, "LinesInsertedFr... | null | null | null | null | # # Lux AI Season 1 Python Tutorial Notebook
# Welcome to Lux AI Season 1! We're glad you could make it! (TODO: add lore here?)
# This notebook takes you step by step on how to develop and compete using **Jupyter Notebooks and Python**. First things first, make sure you have these links at the ready
# - Competition Pag... | false | 0 | 1,299 | 1 | 6 | 1,299 | ||
70478747 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex5 import *
print("Setup complete.")
# # 1.
# デバッグには運も必要だと感じたことはありませんか? 次のプログラムにはバグがあります。そのバグを見つけ出して、正しいコードに修正してみてください!
def has_lucky_number(nums):
"""与えられた数字のリストがラッキーかどうかを返します。ラッキーリストには
7で割り切れる数字が1つ以上含まれてい... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/478/70478747.ipynb | null | null | [{"Id": 70478747, "ScriptId": 19293825, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/07/2021 00:51:18", "VersionNumber": 3.0, "Title": "(\u65e5\u672c\u8a9e\u8a33)Exercise: Loops and List Comprehensions", "EvaluationDate": "08/07/2021", "IsChange": true, "TotalLines":... | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex5 import *
print("Setup complete.")
# # 1.
# デバッグには運も必要だと感じたことはありませんか? 次のプログラムにはバグがあります。そのバグを見つけ出して、正しいコードに修正してみてください!
def has_lucky_number(nums):
"""与えられた数字のリストがラッキーかどうかを返します。ラッキーリストには
7で割り切れる数字が1つ以上含まれている。
"""
for n... | false | 0 | 1,304 | 7 | 6 | 1,304 | ||
70750057 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
im... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/750/70750057.ipynb | null | null | [{"Id": 70750057, "ScriptId": 18993126, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3452800, "CreationDate": "08/08/2021 19:56:23", "VersionNumber": 1.0, "Title": "H4P2 - Speech to Text with LAS", "EvaluationDate": "08/08/2021", "IsChange": true, "TotalLines": 447.0, "LinesInsertedFromPrevious"... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... | false | 0 | 4,820 | 0 | 6 | 4,820 | ||
7074770 | <kaggle_start><code># # Hyperparameters and callbacks
# Source: https://github.com/fastai/fastai_docs/blob/master/dev_nb/004_callbacks.ipynb
# Clean up (to avoid errors)
# Install additional packages
# Download code from previous notebooks
# Download and unzip data
# Create data directories
# Clean up
from nb_003 impor... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0007/074/7074770.ipynb | null | null | [{"Id": 7074770, "ScriptId": 2021162, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 959829, "CreationDate": "11/04/2018 21:05:40", "VersionNumber": 1.0, "Title": "fastai_docs/dev_nb/004_callbacks.ipynb", "EvaluationDate": "11/04/2018", "IsChange": true, "TotalLines": 530.0, "LinesInsertedFromPrev... | null | null | null | null | # # Hyperparameters and callbacks
# Source: https://github.com/fastai/fastai_docs/blob/master/dev_nb/004_callbacks.ipynb
# Clean up (to avoid errors)
# Install additional packages
# Download code from previous notebooks
# Download and unzip data
# Create data directories
# Clean up
from nb_003 import *
from torch impor... | false | 0 | 6,528 | 0 | 6 | 6,528 | ||
94772222 | <kaggle_start><data_title>VOC2012<data_description>Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning<data_name>voc2012
... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0094/772/94772222.ipynb | voc2012 | zhichengwen | [{"Id": 94772222, "ScriptId": 26481417, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3411147, "CreationDate": "05/04/2022 18:53:08", "VersionNumber": 7.0, "Title": "[\u56fe\u50cf\u5206\u5272]Pytorch-VGG/FCN-\u8bed\u4e49\u5206\u5272", "EvaluationDate": "05/04/2022", "IsChange": true, "TotalLines"... | [{"Id": 129113281, "KernelVersionId": 94772222, "SourceDatasetVersionId": 2887798}] | [{"Id": 2887798, "DatasetId": 1768994, "DatasourceVersionId": 2934854, "CreatorUserId": 7951664, "LicenseName": "U.S. Government Works", "CreationDate": "12/05/2021 02:55:48", "VersionNumber": 1.0, "Title": "VOC2012", "Slug": "voc2012", "Subtitle": "Image sets Image sets Image sets Image sets Image sets Image sets", "D... | [{"Id": 1768994, "CreatorUserId": 7951664, "OwnerUserId": 7951664.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2887798.0, "CurrentDatasourceVersionId": 2934854.0, "ForumId": 1791237, "Type": 2, "CreationDate": "12/05/2021 02:55:48", "LastActivityDate": "12/05/2021", "TotalViews": 2390, "TotalDownloads": 23... | [{"Id": 7951664, "UserName": "zhichengwen", "DisplayName": "Kprintf", "RegisterDate": "07/21/2021", "PerformanceTier": 1}] | # **导入必要的包**
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import PIL.Image as pil_image
import matplotlib.pyplot as plt
# **加载自定义的数据******
# * https://zhuanl... | false | 0 | 5,588 | 0 | 92 | 5,588 | ||
94659766 | <kaggle_start><code># # Pattern Recognition in Financial Market
# ## Initialization
# In this section, we initialize the environments with the following steps:
# 1. check all dependencies has been installed
# 2. if not installed, install the dependency with pip
# --------------------------
# DO NOT MODIFY!!!
# --------... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0094/659/94659766.ipynb | null | null | [{"Id": 94659766, "ScriptId": 26185548, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1452696, "CreationDate": "05/03/2022 12:56:18", "VersionNumber": 11.0, "Title": "Experiment of Stock Price Prediction", "EvaluationDate": "05/03/2022", "IsChange": true, "TotalLines": 804.0, "LinesInsertedFromPr... | null | null | null | null | # # Pattern Recognition in Financial Market
# ## Initialization
# In this section, we initialize the environments with the following steps:
# 1. check all dependencies has been installed
# 2. if not installed, install the dependency with pip
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
#... | false | 0 | 9,038 | 0 | 6 | 9,038 | ||
94040247 | <kaggle_start><data_title>kenh14-small<data_name>kenh14small
<code>import yaml
import os
import abc
import time
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
import pandas as pd
import pickle
import random
import re
from tqdm import tqdm
from tensorflow.keras import layers
from tensorflow.... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0094/040/94040247.ipynb | kenh14small | hieunm21 | [{"Id": 94040247, "ScriptId": 26386486, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 8375020, "CreationDate": "04/26/2022 09:21:58", "VersionNumber": 4.0, "Title": "nrms_tf2_k14", "EvaluationDate": "04/26/2022", "IsChange": false, "TotalLines": 2241.0, "LinesInsertedFromPrevious": 0.0, "LinesCha... | [{"Id": 127926474, "KernelVersionId": 94040247, "SourceDatasetVersionId": 3491230}] | [{"Id": 3491230, "DatasetId": 2101503, "DatasourceVersionId": 3543661, "CreatorUserId": 8375020, "LicenseName": "Unknown", "CreationDate": "04/19/2022 09:41:36", "VersionNumber": 1.0, "Title": "kenh14-small", "Slug": "kenh14small", "Subtitle": NaN, "Description": NaN, "VersionNotes": "Initial release", "TotalCompressed... | [{"Id": 2101503, "CreatorUserId": 8375020, "OwnerUserId": 8375020.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 3491230.0, "CurrentDatasourceVersionId": 3543661.0, "ForumId": 2126900, "Type": 2, "CreationDate": "04/19/2022 09:41:36", "LastActivityDate": "04/19/2022", "TotalViews": 491, "TotalDownloads": 5, ... | [{"Id": 8375020, "UserName": "hieunm21", "DisplayName": "Hieu Nguyen Minh", "RegisterDate": "09/17/2021", "PerformanceTier": 0}] | import yaml
import os
import abc
import time
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
import pandas as pd
import pickle
import random
import re
from tqdm import tqdm
from tensorflow.keras import layers
from tensorflow.keras import backend as K
from collections import namedtuple
# det... | false | 0 | 19,583 | 0 | 27 | 19,583 | ||
100993508 | <kaggle_start><code># # **IMPORTING LIBRARIES**
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tifffile as tiff
import cv2
import tensorflow as tf
from tensorflow.keras import layers
from skimage.transform import resize
from sklearn.model_selection import train_test_split
# # **DATA GEN... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0100/993/100993508.ipynb | null | null | [{"Id": 100993508, "ScriptId": 28234493, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5144785, "CreationDate": "07/16/2022 15:35:53", "VersionNumber": 1.0, "Title": "Hacking the Human Body [ Data Gen & Model Archi]", "EvaluationDate": "07/16/2022", "IsChange": true, "TotalLines": 211.0, "LinesIn... | null | null | null | null | # # **IMPORTING LIBRARIES**
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tifffile as tiff
import cv2
import tensorflow as tf
from tensorflow.keras import layers
from skimage.transform import resize
from sklearn.model_selection import train_test_split
# # **DATA GENERATOR**
class image... | false | 0 | 2,341 | 1 | 6 | 2,341 | ||
138711824 | <kaggle_start><code># # Credit EDA Assignment
# # 1. Importing the Necessary Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
from plotly.subplot... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0138/711/138711824.ipynb | null | null | [{"Id": 138711824, "ScriptId": 41703939, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 15729532, "CreationDate": "08/02/2023 17:07:40", "VersionNumber": 1.0, "Title": "Credit EDA", "EvaluationDate": "08/02/2023", "IsChange": true, "TotalLines": 865.0, "LinesInsertedFromPrevious": 865.0, "LinesCha... | null | null | null | null | # # Credit EDA Assignment
# # 1. Importing the Necessary Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
from plotly.subplots import make_subplo... | false | 0 | 8,498 | 1 | 6 | 8,498 | ||
35089966 | <kaggle_start><code>#
# # Table of Contents
# 1. [Align tasks](#align_tasks)
# 1. [Run @yukikubo123's DSL](#run_yuki_dsl)
# 1. [Rollback the predictions](#rollback_the_predictions)
# # Align tasks
# [Back to Table of Contents](#toc)
import warnings
warnings.filterwarnings("ignore")
import os
import json
import numpy a... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/089/35089966.ipynb | null | null | [{"Id": 35089966, "ScriptId": 9793122, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1853329, "CreationDate": "05/30/2020 06:54:25", "VersionNumber": 2.0, "Title": "yukikubo123's DSL with Alignment", "EvaluationDate": "05/30/2020", "IsChange": true, "TotalLines": 6011.0, "LinesInsertedFromPreviou... | null | null | null | null | #
# # Table of Contents
# 1. [Align tasks](#align_tasks)
# 1. [Run @yukikubo123's DSL](#run_yuki_dsl)
# 1. [Rollback the predictions](#rollback_the_predictions)
# # Align tasks
# [Back to Table of Contents](#toc)
import warnings
warnings.filterwarnings("ignore")
import os
import json
import numpy as np
from pathlib im... | false | 0 | 71,693 | 9 | 6 | 71,693 | ||
35900759 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/900/35900759.ipynb | null | null | [{"Id": 35900759, "ScriptId": 9817381, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3699565, "CreationDate": "06/10/2020 17:34:57", "VersionNumber": 23.0, "Title": "M5-acc lstm model", "EvaluationDate": "06/10/2020", "IsChange": true, "TotalLines": 349.0, "LinesInsertedFromPrevious": 76.0, "Line... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, file... | false | 0 | 3,721 | 0 | 6 | 3,721 | ||
35919897 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/919/35919897.ipynb | null | null | [{"Id": 35919897, "ScriptId": 9817086, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3699565, "CreationDate": "06/11/2020 01:08:25", "VersionNumber": 22.0, "Title": "M5-acc boosting", "EvaluationDate": "06/11/2020", "IsChange": true, "TotalLines": 314.0, "LinesInsertedFromPrevious": 4.0, "LinesCh... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, file... | false | 0 | 3,398 | 0 | 6 | 3,398 | ||
35433526 | <kaggle_start><data_title>ResNet-50<data_description># ResNet-50
---
## Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly ref... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/433/35433526.ipynb | resnet50 | null | [{"Id": 35433526, "ScriptId": 9682236, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5079964, "CreationDate": "06/04/2020 09:01:41", "VersionNumber": 13.0, "Title": "kernel54beb4b767", "EvaluationDate": "06/04/2020", "IsChange": true, "TotalLines": 2092.0, "LinesInsertedFromPrevious": 1.0, "Lines... | [{"Id": 39328011, "KernelVersionId": 35433526, "SourceDatasetVersionId": 10040}] | [{"Id": 10040, "DatasetId": 6979, "DatasourceVersionId": 10040, "CreatorUserId": 484516, "LicenseName": "CC0: Public Domain", "CreationDate": "12/13/2017 20:46:19", "VersionNumber": 1.0, "Title": "ResNet-50", "Slug": "resnet50", "Subtitle": "ResNet-50 Pre-trained Model for PyTorch", "Description": "# ResNet-50\n\n---\n... | [{"Id": 6979, "CreatorUserId": 484516, "OwnerUserId": NaN, "OwnerOrganizationId": 1212.0, "CurrentDatasetVersionId": 10040.0, "CurrentDatasourceVersionId": 10040.0, "ForumId": 13659, "Type": 2, "CreationDate": "12/13/2017 20:46:19", "LastActivityDate": "01/12/2018", "TotalViews": 19757, "TotalDownloads": 1912, "TotalVo... | null | # #------------------code for training------------------
#!pip install easydict
#!cp -r ../input/cascadercnn .
# cd cascadercnn/lib
#!python setup.py build develop
# cd ..
#!ls .
# #lr = 0.00125 for one card and one image per batch
#!python train_cascade_fpn.py --dataset pascal_voc --net res50 --epoch 30 --lr_decay_st... | false | 0 | 26,913 | 0 | 608 | 26,913 | ||
35056588 | <kaggle_start><data_title>SIIM ISIC - 224x224 images<data_name>siic-isic-224x224-images
<code># Note: The io with original images is awful. Therefore I created a dataset https://www.kaggle.com/arroqc/siic-isic-224x224-images of images preprocessed to 224x224 size and saved in png (lossless).
# If you train on original ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/056/35056588.ipynb | siic-isic-224x224-images | arroqc | [{"Id": 35056588, "ScriptId": 9744592, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1609480, "CreationDate": "05/29/2020 15:48:29", "VersionNumber": 1.0, "Title": "SIIM ISIC- Pytorch Lightning Starter SEResnext50", "EvaluationDate": "05/29/2020", "IsChange": true, "TotalLines": 380.0, "LinesInse... | [{"Id": 38779547, "KernelVersionId": 35056588, "SourceDatasetVersionId": 1195048}] | [{"Id": 1195048, "DatasetId": 680469, "DatasourceVersionId": 1226267, "CreatorUserId": 1609480, "LicenseName": "Unknown", "CreationDate": "05/28/2020 16:27:52", "VersionNumber": 1.0, "Title": "SIIM ISIC - 224x224 images", "Slug": "siic-isic-224x224-images", "Subtitle": "Preprocessed jpeg images for SIIM ISIC competitio... | [{"Id": 680469, "CreatorUserId": 1609480, "OwnerUserId": 1609480.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1195048.0, "CurrentDatasourceVersionId": 1226267.0, "ForumId": 695012, "Type": 2, "CreationDate": "05/28/2020 16:27:52", "LastActivityDate": "05/28/2020", "TotalViews": 8881, "TotalDownloads": 1527... | [{"Id": 1609480, "UserName": "arroqc", "DisplayName": "Arnaud Roussel", "RegisterDate": "02/04/2018", "PerformanceTier": 3}] | # Note: The io with original images is awful. Therefore I created a dataset https://www.kaggle.com/arroqc/siic-isic-224x224-images of images preprocessed to 224x224 size and saved in png (lossless).
# If you train on original jpeg large imagesm I have put the right lines of code in comments with the added comments : # ... | false | 0 | 4,576 | 0 | 45 | 4,576 | ||
35538162 | <kaggle_start><code># Install `tensorflow-datasets`.
# Define wrapper.
# adapted from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/538/35538162.ipynb | null | null | [{"Id": 35538162, "ScriptId": 9936942, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2003505, "CreationDate": "06/05/2020 18:23:26", "VersionNumber": 3.0, "Title": "TFDS Example", "EvaluationDate": "06/05/2020", "IsChange": true, "TotalLines": 40.0, "LinesInsertedFromPrevious": 4.0, "LinesChanged... | null | null | null | null | # Install `tensorflow-datasets`.
# Define wrapper.
# adapted from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _info(self):
... | false | 0 | 300 | 0 | 6 | 300 | ||
35536478 | <kaggle_start><code># Install `tensorflow-datasets`.
# Define wrapper.
# from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/536/35536478.ipynb | null | null | [{"Id": 35536478, "ScriptId": 9936942, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2003505, "CreationDate": "06/05/2020 17:52:48", "VersionNumber": 1.0, "Title": "TFDS Example", "EvaluationDate": "06/05/2020", "IsChange": true, "TotalLines": 42.0, "LinesInsertedFromPrevious": 42.0, "LinesChange... | null | null | null | null | # Install `tensorflow-datasets`.
# Define wrapper.
# from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _info(self):
... | false | 0 | 325 | 0 | 6 | 325 | ||
42613117 | <kaggle_start><code># # Project Assignment Problem Statement
# * There are S students, P projects, and each project should have at least R students ( R < S/P)
# * Each student rank orders at most K (K < P, for example K = 5) projects according to their preferences
# * After a student is assigned to a project, the quali... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/613/42613117.ipynb | null | null | [{"Id": 42613117, "ScriptId": 11715103, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1892767, "CreationDate": "09/13/2020 22:09:58", "VersionNumber": 1.0, "Title": "project assignment", "EvaluationDate": "09/13/2020", "IsChange": true, "TotalLines": 70.0, "LinesInsertedFromPrevious": 70.0, "Line... | null | null | null | null | # # Project Assignment Problem Statement
# * There are S students, P projects, and each project should have at least R students ( R < S/P)
# * Each student rank orders at most K (K < P, for example K = 5) projects according to their preferences
# * After a student is assigned to a project, the quality of assignment fro... | false | 0 | 722 | 1 | 6 | 722 | ||
42552163 | <kaggle_start><code># # Tic Tac Toe
# BMS College of Engineering - Dr Kavitha Sooda
# Create a 3x3 tic tac toe board of "" strings for each value
board = None
# Create a function to display your board
def display_board(board):
pass
display_board(board)
# Create a function to check if anyone won, Use marks "X"... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/552/42552163.ipynb | null | null | [{"Id": 42552163, "ScriptId": 11684452, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3482267, "CreationDate": "09/13/2020 02:31:24", "VersionNumber": 1.0, "Title": "AI-Lab Program 1", "EvaluationDate": "09/13/2020", "IsChange": true, "TotalLines": 57.0, "LinesInsertedFromPrevious": 57.0, "LinesC... | null | null | null | null | # # Tic Tac Toe
# BMS College of Engineering - Dr Kavitha Sooda
# Create a 3x3 tic tac toe board of "" strings for each value
board = None
# Create a function to display your board
def display_board(board):
pass
display_board(board)
# Create a function to check if anyone won, Use marks "X" or "O"
def check_wi... | false | 0 | 362 | 0 | 6 | 362 | ||
42448247 | <kaggle_start><code>import os
import warnings
from tqdm import tqdm
import pandas as pd
import numpy as np
from ml_stratifiers import MultilabelStratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.base import clone
from sklearn.linear_model import LogisticRegression
from sklearn.multioutput imp... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/448/42448247.ipynb | null | null | [{"Id": 42448247, "ScriptId": 11620414, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1309204, "CreationDate": "09/11/2020 11:59:42", "VersionNumber": 7.0, "Title": "MoA :: OOF & non-DL models", "EvaluationDate": "09/11/2020", "IsChange": true, "TotalLines": 241.0, "LinesInsertedFromPrevious": 54... | null | null | null | null | import os
import warnings
from tqdm import tqdm
import pandas as pd
import numpy as np
from ml_stratifiers import MultilabelStratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.base import clone
from sklearn.linear_model import LogisticRegression
from sklearn.multioutput import MultiOutputClass... | false | 0 | 2,832 | 0 | 6 | 2,832 | ||
42711809 | <kaggle_start><data_title>Grid Loss Prediction Dataset<data_description>### Context
A power grid transports the electricity from power producers to the consumers. But all that is produced is not delivered to the customers. Some parts of it are lost in either transmission or distribution. In Norway, the grid companies ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/711/42711809.ipynb | grid-loss-time-series-dataset | trnderenergikraft | [{"Id": 42711809, "ScriptId": 11740565, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1203660, "CreationDate": "09/15/2020 07:29:31", "VersionNumber": 2.0, "Title": "Grid loss demo and persistence model", "EvaluationDate": "09/15/2020", "IsChange": false, "TotalLines": 93.0, "LinesInsertedFromPre... | [{"Id": 52282979, "KernelVersionId": 42711809, "SourceDatasetVersionId": 1487717}] | [{"Id": 1487717, "DatasetId": 746802, "DatasourceVersionId": 1521634, "CreatorUserId": 5773405, "LicenseName": "CC BY-SA 4.0", "CreationDate": "09/14/2020 14:35:19", "VersionNumber": 2.0, "Title": "Grid Loss Prediction Dataset", "Slug": "grid-loss-time-series-dataset", "Subtitle": "A time series dataset for predicting ... | [{"Id": 746802, "CreatorUserId": 1203660, "OwnerUserId": 5773405.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1546931.0, "CurrentDatasourceVersionId": 1581682.0, "ForumId": 761702, "Type": 2, "CreationDate": "06/30/2020 08:44:25", "LastActivityDate": "06/30/2020", "TotalViews": 6191, "TotalDownloads": 433,... | [{"Id": 5773405, "UserName": "trnderenergikraft", "DisplayName": "Tr\u00f8nderEnergi Kraft", "RegisterDate": "09/14/2020", "PerformanceTier": 0}] | # # Grid loss demonstration and Persistence model
# This notebook will give a demo for how to use the dataset. The pupose of this notebook is to provide the persistence model for predicting the grid loss.
# **Persistence model:**
# Persistence model is a well used baseline time series perdiction. It assumes that time s... | false | 1 | 1,101 | 0 | 1,513 | 1,101 | ||
132007580 | <kaggle_start><code># # **Titanic survival prediction with Decision Tree**
# Hello there, this notebook will go through the process of my data preprocessing approach and building a decision tree using sklearn. What you can expect from this notebook:
# 1. Feature enginneering with pipeline
# 2. Building a simple decisio... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0132/007/132007580.ipynb | null | null | [{"Id": 132007580, "ScriptId": 39373078, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 12917908, "CreationDate": "06/02/2023 16:54:28", "VersionNumber": 3.0, "Title": "Prediction with Decision Tree", "EvaluationDate": "06/02/2023", "IsChange": true, "TotalLines": 304.0, "LinesInsertedFromPrevious... | null | null | null | null | # # **Titanic survival prediction with Decision Tree**
# Hello there, this notebook will go through the process of my data preprocessing approach and building a decision tree using sklearn. What you can expect from this notebook:
# 1. Feature enginneering with pipeline
# 2. Building a simple decision tree using sklearn... | false | 0 | 3,319 | 2 | 6 | 3,319 | ||
132554970 | <kaggle_start><data_title>Flickr-Faces-HQ (FFHQ) small<data_description>This is a small version of FFHQ with 3143 photos.
Flickr-Faces-HQ (FFHQ) is an image dataset containing high-quality images of human faces. It is provided by NVIDIA under the Creative Commons BY-NC-SA 4.0 license. It offers 70,000 PNG images at 10... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0132/554/132554970.ipynb | faces-dataset-small | tommykamaz | [{"Id": 132554970, "ScriptId": 39497739, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3910696, "CreationDate": "06/06/2023 18:55:17", "VersionNumber": 3.0, "Title": "faceDCGAN", "EvaluationDate": "06/06/2023", "IsChange": true, "TotalLines": 599.0, "LinesInsertedFromPrevious": 86.0, "LinesChange... | [{"Id": 190049945, "KernelVersionId": 132554970, "SourceDatasetVersionId": 3684316}] | [{"Id": 3684316, "DatasetId": 2204890, "DatasourceVersionId": 3738480, "CreatorUserId": 8975186, "LicenseName": "Attribution 4.0 International (CC BY 4.0)", "CreationDate": "05/23/2022 17:12:59", "VersionNumber": 1.0, "Title": "Flickr-Faces-HQ (FFHQ) small", "Slug": "faces-dataset-small", "Subtitle": "3143 photos of Fl... | [{"Id": 2204890, "CreatorUserId": 8975186, "OwnerUserId": 8975186.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 3684316.0, "CurrentDatasourceVersionId": 3738480.0, "ForumId": 2231003, "Type": 2, "CreationDate": "05/23/2022 17:12:59", "LastActivityDate": "05/23/2022", "TotalViews": 2531, "TotalDownloads": 12... | [{"Id": 8975186, "UserName": "tommykamaz", "DisplayName": "Grigory Soldatov", "RegisterDate": "11/23/2021", "PerformanceTier": 1}] | #
# Школа глубокого обучения ФПМИ МФТИ
# Домашнее задание. Generative adversarial networks
# В этом домашнем задании вы обучите GAN генерировать лица людей и посмотрите на то, как можно оценивать качество генерации
import os
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import tor... | false | 0 | 5,959 | 1 | 146 | 5,959 | ||
48305609 | <kaggle_start><code># This is a two part tutorial series on TF-Agents
# Part 1 : https://www.kaggle.com/usharengaraju/tfagents-environment-policy-driver
# Part 2 : https://www.kaggle.com/usharengaraju/tf-agents-replay-buffer-network-checkpointer
# Credit : The article series has been adapted from the official tensorflo... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/305/48305609.ipynb | null | null | [{"Id": 48305609, "ScriptId": 7934748, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 373959, "CreationDate": "12/01/2020 20:53:25", "VersionNumber": 43.0, "Title": "TFAgents-Environment , Policy , Driver", "EvaluationDate": "12/01/2020", "IsChange": false, "TotalLines": 320.0, "LinesInsertedFromP... | null | null | null | null | # This is a two part tutorial series on TF-Agents
# Part 1 : https://www.kaggle.com/usharengaraju/tfagents-environment-policy-driver
# Part 2 : https://www.kaggle.com/usharengaraju/tf-agents-replay-buffer-network-checkpointer
# Credit : The article series has been adapted from the official tensorflow documentation.
# #... | false | 0 | 2,714 | 26 | 6 | 2,714 | ||
48202409 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
im... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/202/48202409.ipynb | null | null | [{"Id": 48202409, "ScriptId": 13002333, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6204353, "CreationDate": "11/30/2020 15:56:58", "VersionNumber": 2.0, "Title": "notebook05985af1f6", "EvaluationDate": "11/30/2020", "IsChange": false, "TotalLines": 238.0, "LinesInsertedFromPrevious": 0.0, "Lin... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... | false | 0 | 1,897 | 0 | 6 | 1,897 | ||
48950175 | <kaggle_start><code>## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: person.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
class Person:
"""An example class to show Python ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/950/48950175.ipynb | null | null | [{"Id": 48950175, "ScriptId": 13334608, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5756551, "CreationDate": "12/10/2020 02:55:34", "VersionNumber": 1.0, "Title": "lecture_13", "EvaluationDate": "12/10/2020", "IsChange": true, "TotalLines": 165.0, "LinesInsertedFromPrevious": 165.0, "LinesChang... | null | null | null | null | ## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: person.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
class Person:
"""An example class to show Python Class definitions"""... | false | 0 | 1,396 | 1 | 6 | 1,396 | ||
48225430 | <kaggle_start><data_title>The Enron Email Dataset<data_description>The Enron email dataset contains approximately 500,000 emails generated by employees of the Enron Corporation. It was obtained by the Federal Energy Regulatory Commission during its investigation of Enron's collapse.
This is the May 7, 2015 Version of ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/225/48225430.ipynb | enron-email-dataset | wcukierski | [{"Id": 48225430, "ScriptId": 13228744, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4409920, "CreationDate": "11/30/2020 21:33:21", "VersionNumber": 1.0, "Title": "MIS 437 Module 9", "EvaluationDate": "11/30/2020", "IsChange": false, "TotalLines": 487.0, "LinesInsertedFromPrevious": 0.0, "Lines... | [{"Id": 59521244, "KernelVersionId": 48225430, "SourceDatasetVersionId": 120}] | [{"Id": 120, "DatasetId": 55, "DatasourceVersionId": 120, "CreatorUserId": 3258, "LicenseName": "Data files \u00a9 Original Authors", "CreationDate": "06/16/2016 20:55:19", "VersionNumber": 2.0, "Title": "The Enron Email Dataset", "Slug": "enron-email-dataset", "Subtitle": "500,000+ emails from 150 employees of the Enr... | [{"Id": 55, "CreatorUserId": 3258, "OwnerUserId": 3258.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 120.0, "CurrentDatasourceVersionId": 120.0, "ForumId": 1322, "Type": 2, "CreationDate": "06/07/2016 16:46:57", "LastActivityDate": "02/05/2018", "TotalViews": 370722, "TotalDownloads": 41492, "TotalVotes": 6... | [{"Id": 3258, "UserName": "wcukierski", "DisplayName": "Will Cukierski", "RegisterDate": "10/13/2010", "PerformanceTier": 5}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
from sklearn.preprocessing import normalize
from sklearn.metrics import pairwi... | false | 0 | 4,449 | 0 | 136 | 4,449 | ||
45894332 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from functools import partial
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all file... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/894/45894332.ipynb | null | null | [{"Id": 45894332, "ScriptId": 12596012, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6065461, "CreationDate": "10/31/2020 15:28:39", "VersionNumber": 2.0, "Title": "Gradient Decent", "EvaluationDate": "10/31/2020", "IsChange": true, "TotalLines": 256.0, "LinesInsertedFromPrevious": 7.0, "LinesCh... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from functools import partial
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input di... | false | 0 | 2,622 | 0 | 6 | 2,622 | ||
45605603 | <kaggle_start><code># # Deep Q-learner starter code
# **Work in progress!** Please forgive lack of clarity, bugs, and typos.
# This notebook aims to demonstrate creating a deep Q-learner using Keras and train it on the GFootball enviroment. It will focus on the coded need to train a deep q-learner agent, rather than th... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/605/45605603.ipynb | null | null | [{"Id": 45605603, "ScriptId": 12495311, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4999684, "CreationDate": "10/27/2020 12:44:35", "VersionNumber": 3.0, "Title": "Wstawic115v3", "EvaluationDate": "10/27/2020", "IsChange": true, "TotalLines": 794.0, "LinesInsertedFromPrevious": 4.0, "LinesChang... | null | null | null | null | # # Deep Q-learner starter code
# **Work in progress!** Please forgive lack of clarity, bugs, and typos.
# This notebook aims to demonstrate creating a deep Q-learner using Keras and train it on the GFootball enviroment. It will focus on the coded need to train a deep q-learner agent, rather than theory. Hopefully it w... | false | 0 | 7,968 | 0 | 6 | 7,968 | ||
45449554 | <kaggle_start><code># El problema de la mochila (Knapsack problem - KSP) consiste en encontrar, a partir de los objetos disponibles, el conjunto de objetos que quepa en la mochila cuyo valor acumulado sea máximo. Al igual que en el problema anterior, este problema es fácilmente resoluble haciendo una comprobación de to... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/449/45449554.ipynb | null | null | [{"Id": 45449554, "ScriptId": 12486770, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1743598, "CreationDate": "10/25/2020 09:27:07", "VersionNumber": 1.0, "Title": "Practica 4 AP KS 2020", "EvaluationDate": "10/25/2020", "IsChange": false, "TotalLines": 148.0, "LinesInsertedFromPrevious": 0.0, "... | null | null | null | null | # El problema de la mochila (Knapsack problem - KSP) consiste en encontrar, a partir de los objetos disponibles, el conjunto de objetos que quepa en la mochila cuyo valor acumulado sea máximo. Al igual que en el problema anterior, este problema es fácilmente resoluble haciendo una comprobación de todas las posibles com... | false | 0 | 1,909 | 0 | 6 | 1,909 | ||
45013469 | <kaggle_start><code># # 8 Puzzle Problem
# BMS College of Engineering - Dr Kavitha Sooda
# BMS College of Engineering - Dr Nagarathna N
# BMS College of Engineering - Prof G R Asha
# ##### Class 5C
# ## Objective
# Given a 3×3 board with 8 tiles and one empty space
# - Move the numbers around to match the final configu... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/013/45013469.ipynb | null | null | [{"Id": 45013469, "ScriptId": 12365973, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5817315, "CreationDate": "10/19/2020 05:15:12", "VersionNumber": 1.0, "Title": "AI - Lab Program 4", "EvaluationDate": "10/19/2020", "IsChange": true, "TotalLines": 121.0, "LinesInsertedFromPrevious": 63.0, "Lin... | null | null | null | null | # # 8 Puzzle Problem
# BMS College of Engineering - Dr Kavitha Sooda
# BMS College of Engineering - Dr Nagarathna N
# BMS College of Engineering - Prof G R Asha
# ##### Class 5C
# ## Objective
# Given a 3×3 board with 8 tiles and one empty space
# - Move the numbers around to match the final configuration using the emp... | false | 0 | 1,199 | 0 | 6 | 1,199 | ||
32923749 | <kaggle_start><data_title>densenet121_256<data_name>densenet121-256
<code>import os
import math
import openslide
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import albumentations
from tqdm import tqdm
from joblib import Parallel, delayed
from matplotlib i... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/923/32923749.ipynb | densenet121-256 | kaushal2896 | [{"Id": 32923749, "ScriptId": 9153730, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1905996, "CreationDate": "04/29/2020 10:12:59", "VersionNumber": 13.0, "Title": "PANDA: DenseNet121 Inference", "EvaluationDate": "04/29/2020", "IsChange": true, "TotalLines": 391.0, "LinesInsertedFromPrevious": ... | [{"Id": 35791690, "KernelVersionId": 32923749, "SourceDatasetVersionId": 1117024}] | [{"Id": 1117024, "DatasetId": 625369, "DatasourceVersionId": 1147361, "CreatorUserId": 1905996, "LicenseName": "Unknown", "CreationDate": "04/29/2020 09:31:01", "VersionNumber": 3.0, "Title": "densenet121_256", "Slug": "densenet121-256", "Subtitle": NaN, "Description": NaN, "VersionNotes": "v3", "TotalCompressedBytes":... | [{"Id": 625369, "CreatorUserId": 1905996, "OwnerUserId": 1905996.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1121883.0, "CurrentDatasourceVersionId": 1152271.0, "ForumId": 639561, "Type": 2, "CreationDate": "04/28/2020 12:06:07", "LastActivityDate": "04/28/2020", "TotalViews": 1439, "TotalDownloads": 4, "... | [{"Id": 1905996, "UserName": "kaushal2896", "DisplayName": "Kaushal Shah", "RegisterDate": "05/12/2018", "PerformanceTier": 2}] | import os
import math
import openslide
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import albumentations
from tqdm import tqdm
from joblib import Parallel, delayed
from matplotlib import pyplot as plt
from PIL import Image, ImageChops
import cv2
import to... | false | 0 | 4,297 | 0 | 34 | 4,297 | ||
32853136 | <kaggle_start><data_title>MNIST Dataset<data_description>### Context
MNIST is a subset of a larger set available from NIST (it's copied from http://yann.lecun.com/exdb/mnist/)
### Content
The MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples. .
Four files ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/853/32853136.ipynb | mnist-dataset | hojjatk | [{"Id": 32853136, "ScriptId": 9080374, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2708391, "CreationDate": "04/28/2020 11:04:59", "VersionNumber": 6.0, "Title": "No tf, pytorch: Create Neural Network From Scratch", "EvaluationDate": "04/28/2020", "IsChange": true, "TotalLines": 593.0, "LinesIn... | [{"Id": 35697682, "KernelVersionId": 32853136, "SourceDatasetVersionId": 242592}] | [{"Id": 242592, "DatasetId": 102285, "DatasourceVersionId": 254413, "CreatorUserId": 1840515, "LicenseName": "Data files \u00a9 Original Authors", "CreationDate": "01/08/2019 13:01:57", "VersionNumber": 1.0, "Title": "MNIST Dataset", "Slug": "mnist-dataset", "Subtitle": "The MNIST database of handwritten digits (http:... | [{"Id": 102285, "CreatorUserId": 1840515, "OwnerUserId": 1840515.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 242592.0, "CurrentDatasourceVersionId": 254413.0, "ForumId": 111993, "Type": 2, "CreationDate": "01/08/2019 13:01:57", "LastActivityDate": "01/08/2019", "TotalViews": 113247, "TotalDownloads": 1660... | [{"Id": 1840515, "UserName": "hojjatk", "DisplayName": "Hojjat Khodabakhsh", "RegisterDate": "04/20/2018", "PerformanceTier": 0}] | # 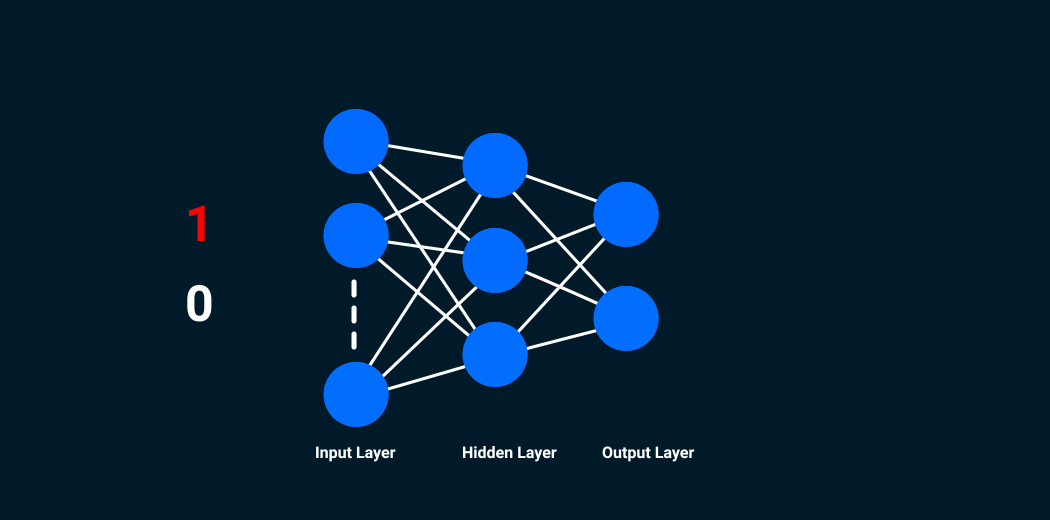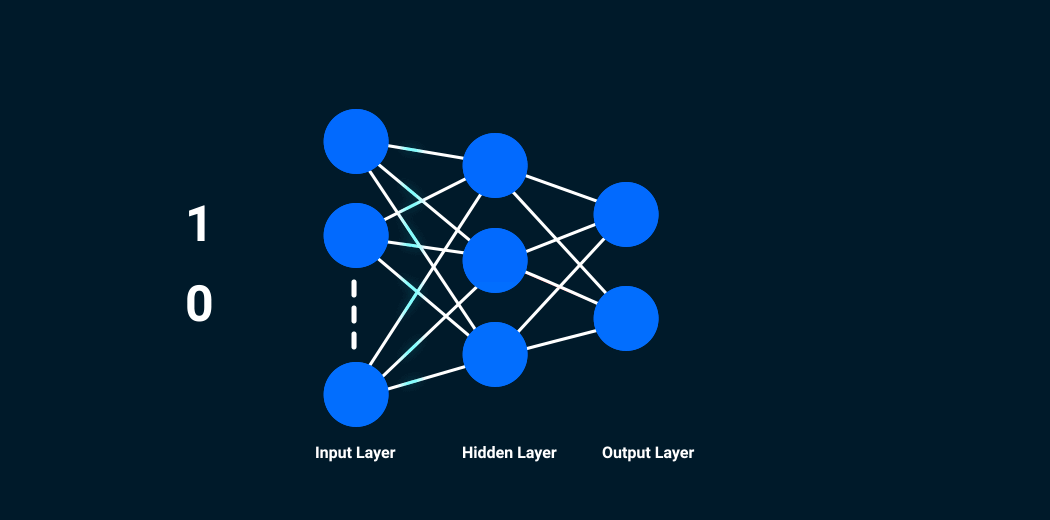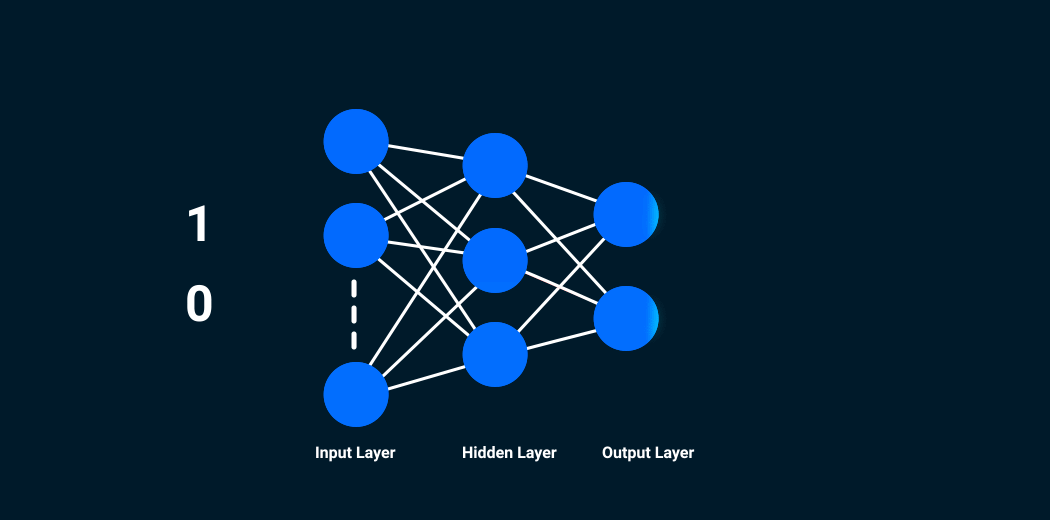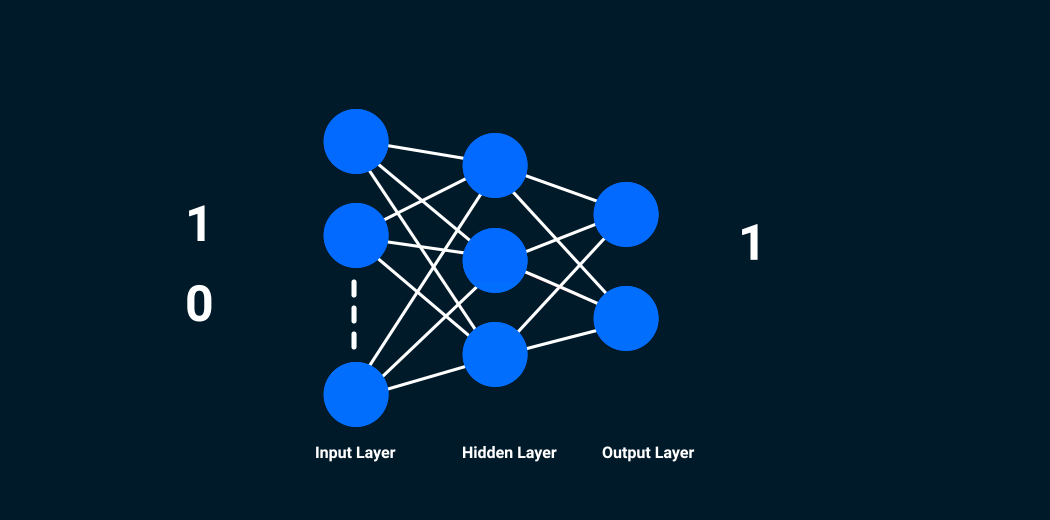
# # Setup
# Import Libraries
import numpy as np
import math
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import rcParams
from preprocessing import *
from mathutils import *
sns.set(style="whitegrid")
rcParams["figure.figsi... | false | 0 | 9,046 | 1 | 237 | 9,046 | ||
32195719 | <kaggle_start><data_title>COVID-19 Open Research Dataset Challenge (CORD-19)<data_description>### Dataset Description
In response to the COVID-19 pandemic, the White House and a coalition of leading research groups have prepared the COVID-19 Open Research Dataset (CORD-19). CORD-19 is a resource of over 51,000 scholar... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/195/32195719.ipynb | CORD-19-research-challenge | null | [{"Id": 32195719, "ScriptId": 8850712, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 273193, "CreationDate": "04/17/2020 18:31:59", "VersionNumber": 8.0, "Title": "CORD-19: Abstract and Conclusion Text Embedding", "EvaluationDate": "04/17/2020", "IsChange": true, "TotalLines": 1268.0, "LinesInser... | [{"Id": 34837114, "KernelVersionId": 32195719, "SourceDatasetVersionId": 1073914}, {"Id": 34837113, "KernelVersionId": 32195719, "SourceDatasetVersionId": 1071857}, {"Id": 34837112, "KernelVersionId": 32195719, "SourceDatasetVersionId": 1063983}] | [{"Id": 1073914, "DatasetId": 551982, "DatasourceVersionId": 1103617, "CreatorUserId": 1314380, "LicenseName": "Other (specified in description)", "CreationDate": "04/11/2020 13:32:24", "VersionNumber": 7.0, "Title": "COVID-19 Open Research Dataset Challenge (CORD-19)", "Slug": "CORD-19-research-challenge", "Subtitle":... | [{"Id": 551982, "CreatorUserId": 2931338, "OwnerUserId": NaN, "OwnerOrganizationId": 3737.0, "CurrentDatasetVersionId": 3756201.0, "CurrentDatasourceVersionId": 3810704.0, "ForumId": 565591, "Type": 2, "CreationDate": "03/12/2020 20:05:08", "LastActivityDate": "03/12/2020", "TotalViews": 4468011, "TotalDownloads": 1639... | null | # # Introduction
# This project uses pretrained text classifier model to get the embedding in order to find the nearest texts (or sentences) in a collection of articles. The texts to find are from the following questions.
# - Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination o... | false | 0 | 10,448 | 0 | 1,020 | 10,448 | ||
32224913 | <kaggle_start><code># # Preperation
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input direc... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/224/32224913.ipynb | null | null | [{"Id": 32224913, "ScriptId": 8825052, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4714017, "CreationDate": "04/18/2020 09:04:12", "VersionNumber": 7.0, "Title": "Step by step Pipeline with pandas Dataframes", "EvaluationDate": "04/18/2020", "IsChange": true, "TotalLines": 751.0, "LinesInserted... | null | null | null | null | # # Preperation
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for ... | false | 0 | 7,966 | 0 | 6 | 7,966 | ||
32525073 | <kaggle_start><code># > # M5 Statistical Benchmarks with Python classes
# This notebook provides some of the **statistical benchmark models** proposed by **M5 organizers** (for more details about these models and for more general information on the M5 competition, please refer to the [M5 Competitors Guide](https://mk0m... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/525/32525073.ipynb | null | null | [{"Id": 32525073, "ScriptId": 8511938, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 493741, "CreationDate": "04/23/2020 09:45:55", "VersionNumber": 14.0, "Title": "M5 Statistical Benchmarks with Python classes", "EvaluationDate": "04/23/2020", "IsChange": true, "TotalLines": 1295.0, "LinesInsert... | null | null | null | null | # > # M5 Statistical Benchmarks with Python classes
# This notebook provides some of the **statistical benchmark models** proposed by **M5 organizers** (for more details about these models and for more general information on the M5 competition, please refer to the [M5 Competitors Guide](https://mk0mcompetitiont8ake.kin... | false | 0 | 13,144 | 2 | 6 | 13,144 | ||
32085077 | <kaggle_start><data_title>country health indicators<data_description>This dataset combines multiple open data sets for Covid-19 cases and deaths ([kaggle1](https://www.kaggle.com/c/covid19-global-forecasting-week-3/data)), Death causes ([ourworldindata1](https://ourworldindata.org/grapher/share-of-total-disease-burden-... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/085/32085077.ipynb | country-health-indicators | nxpnsv | [{"Id": 32085077, "ScriptId": 8950160, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 85138, "CreationDate": "04/15/2020 23:30:59", "VersionNumber": 2.0, "Title": "TBTB-W4", "EvaluationDate": "04/15/2020", "IsChange": true, "TotalLines": 584.0, "LinesInsertedFromPrevious": 58.0, "LinesChangedFromP... | [{"Id": 34667158, "KernelVersionId": 32085077, "SourceDatasetVersionId": 1064891}] | [{"Id": 1064891, "DatasetId": 585107, "DatasourceVersionId": 1094467, "CreatorUserId": 85138, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "04/07/2020 11:12:41", "VersionNumber": 6.0, "Title": "country health indicators", "Slug": "country-health-indicators", "Subtitle": "Health indicator relevant to covid19 death ... | [{"Id": 585107, "CreatorUserId": 85138, "OwnerUserId": 85138.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1064891.0, "CurrentDatasourceVersionId": 1094467.0, "ForumId": 598971, "Type": 2, "CreationDate": "04/03/2020 11:40:29", "LastActivityDate": "04/03/2020", "TotalViews": 16569, "TotalDownloads": 1478, "... | [{"Id": 85138, "UserName": "nxpnsv", "DisplayName": "nxpnsv", "RegisterDate": "02/14/2013", "PerformanceTier": 1}] | # ## Imports
# Imports
import os
from abc import ABCMeta, abstractmethod
from typing import Dict, List, Tuple, Union
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_log_error
from scipy.optimize.minpack import curve_fit
from scipy.opt... | false | 2 | 6,792 | 0 | 434 | 6,792 | ||
32437219 | <kaggle_start><code>import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
def weights_init(m):
if type(m) == nn.Linear:
m.weight.data.normal_(0.0, 1e-3)
m.bias.data.fill_(0.0)
def update_lr(optimizer, ... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/437/32437219.ipynb | null | null | [{"Id": 32437219, "ScriptId": 9050975, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2853217, "CreationDate": "04/21/2020 21:12:46", "VersionNumber": 1.0, "Title": "AMLHW3", "EvaluationDate": "04/21/2020", "IsChange": true, "TotalLines": 346.0, "LinesInsertedFromPrevious": 346.0, "LinesChangedFro... | null | null | null | null | import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
def weights_init(m):
if type(m) == nn.Linear:
m.weight.data.normal_(0.0, 1e-3)
m.bias.data.fill_(0.0)
def update_lr(optimizer, lr):
for param_g... | false | 0 | 2,876 | 0 | 6 | 2,876 | ||
32970077 | <kaggle_start><data_title>Face Detection in Images<data_description>### Context
Faces in images marked with bounding boxes. Have around 500 images with around 1100 faces manually tagged via bounding box.
To visualize the dataset and see how the dataset looks (actual images with tags) please see: https://dataturks.com... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/970/32970077.ipynb | face-detection-in-images | dataturks | [{"Id": 32970077, "ScriptId": 9086782, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4456277, "CreationDate": "04/30/2020 01:26:28", "VersionNumber": 8.0, "Title": "CSCI 4622: Final Project", "EvaluationDate": "04/30/2020", "IsChange": true, "TotalLines": 200.0, "LinesInsertedFromPrevious": 118.0... | [{"Id": 35851505, "KernelVersionId": 32970077, "SourceDatasetVersionId": 54972}, {"Id": 35851504, "KernelVersionId": 32970077, "SourceDatasetVersionId": 37705}, {"Id": 35851503, "KernelVersionId": 32970077, "SourceDatasetVersionId": 18147}, {"Id": 35851506, "KernelVersionId": 32970077, "SourceDatasetVersionId": 1104205... | [{"Id": 54972, "DatasetId": 36341, "DatasourceVersionId": 57374, "CreatorUserId": 1853660, "LicenseName": "Unknown", "CreationDate": "07/12/2018 09:34:14", "VersionNumber": 1.0, "Title": "Face Detection in Images", "Slug": "face-detection-in-images", "Subtitle": "Image bounding box dataset to detect faces in images", "... | [{"Id": 36341, "CreatorUserId": 1853660, "OwnerUserId": 1853660.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 54972.0, "CurrentDatasourceVersionId": 57374.0, "ForumId": 44755, "Type": 2, "CreationDate": "07/12/2018 09:34:14", "LastActivityDate": "07/12/2018", "TotalViews": 598479, "TotalDownloads": 23774, "... | [{"Id": 1853660, "UserName": "dataturks", "DisplayName": "DataTurks", "RegisterDate": "04/24/2018", "PerformanceTier": 2}] | import numpy as np
import pandas as pd
import cv2 as cv
import os
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
import glob
# https://realpython.com/traditional-face-detection-python/
face_cascade = cv.CascadeClassifier(
"/kaggle/input/haarcascades/haarcascade_frontalface_alt.xml"
)
def detect_f... | false | 0 | 2,220 | 0 | 137 | 2,220 | ||
135796633 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
im... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0135/796/135796633.ipynb | null | null | [{"Id": 135796633, "ScriptId": 40539752, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 13503132, "CreationDate": "07/05/2023 10:09:03", "VersionNumber": 4.0, "Title": "Enzyme\ud83e\udda0", "EvaluationDate": "07/05/2023", "IsChange": true, "TotalLines": 115.0, "LinesInsertedFromPrevious": 74.0, "L... | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... | false | 0 | 1,099 | 0 | 6 | 1,099 | ||
469856 | <kaggle_start><code># # @author Julien WUTHRICH
import pandas as pd
import numpy as np
df = pd.read_csv("../input/train_ver2.csv", nrows=100000)
import time
def timeit(method):
def timed(*args, **kw):
ts = time.time()
result = method(*args, **kw)
te = time.time()
print("Duration =... | /fsx/loubna/kaggle_data/kaggle-code-data/data/0000/469/469856.ipynb | null | null | [{"Id": 469856, "ScriptId": 123325, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 576054, "CreationDate": "11/27/2016 16:45:54", "VersionNumber": 8.0, "Title": "Create new columns based on fuzzy logic", "EvaluationDate": "11/27/2016", "IsChange": true, "TotalLines": NaN, "LinesInsertedFromPreviou... | null | null | null | null | # # @author Julien WUTHRICH
import pandas as pd
import numpy as np
df = pd.read_csv("../input/train_ver2.csv", nrows=100000)
import time
def timeit(method):
def timed(*args, **kw):
ts = time.time()
result = method(*args, **kw)
te = time.time()
print("Duration = {}".format(te - ts)... | false | 0 | 2,423 | 0 | 6 | 2,423 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.