---
license: mit
language:
- en
task_categories:
- question-answering
size_categories:
- n<1K
pretty_name: Brainteaser
---
# The Brainteaser dataset
[](https://arxiv.org/abs/2505.10844)
[](https://openreview.net/forum?id=3oQDkmW72a)
[](https://openreview.net/pdf?id=3oQDkmW72a)
[](https://huggingface.co/datasets/ChenLiu1996/Brainteaser)
[](https://github.com/stephenxia1/brainteasers/)
This is a dataset concurrently released with our paper
[**Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models**](https://arxiv.org/abs/2505.10844), NeurIPS 2025.
[ ](https://arxiv.org/pdf/2505.10844)
## Citation
If you use this dataset, please cite our paper:
```bibtex
@article{han2025creativity,
title={Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models},
author={Han, Simeng and Dai, Howard and Xia, Stephen and Zhang, Grant and Liu, Chen and Chen, Lichang and Nguyen, Hoang Huy and Mei, Hongyuan and Mao, Jiayuan and McCoy, R. Thomas},
journal={Advances in neural information processing systems},
year={2025}
}
```
## Highlights
1. We introduce a **novel benchmark dataset**, BRAINTEASER, which uses brainteasers to evaluate the **reasoning abilities of LLMs**.
2. The Math and Logic datasets were curated by scraping problem-solving and reasoning questions from the [Braingle](https://www.braingle.com/brainteasers/All.html) website, an online platform of puzzles and brain teasers.
3. Authored by **expert problem solvers**, BRAINTEASER features diverse puzzle styles and complexities, aiming to **isolate models’ reasoning abilities rather than their memorization of formulas**.
4. BRAINTEASER is exclusively centered on **mathematical and logical puzzles**, all authored by expert problem solvers with demonstrated proficiency across a wide range of puzzle types.
5. As **quality control**, we conducted one round of **manual inspection** of all problems in BRAINTEASER done by college students who belong to a math club; these students have extensive experience in solving competition-level math problems.
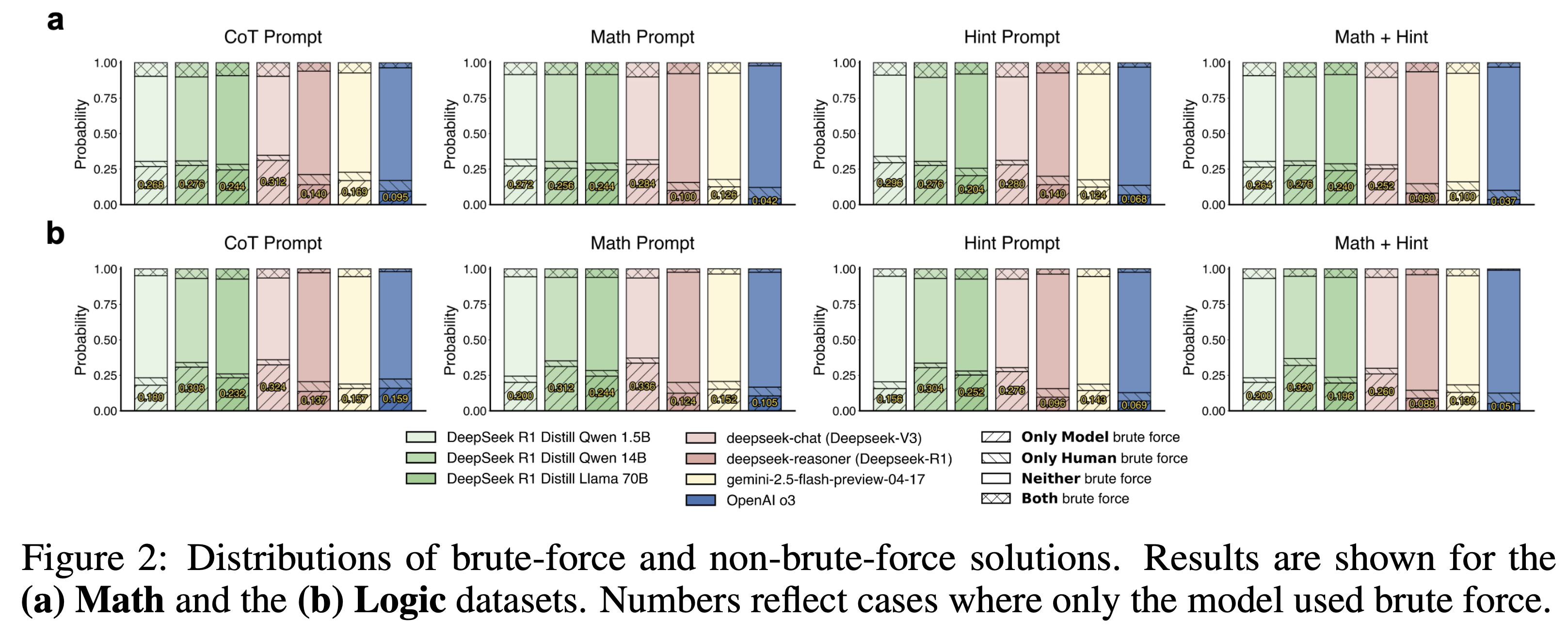
6. During manual inspection, low-quality and ambiguously described problems were removed, leaving 242 Math and 236 Logic problems in the dataset. The same annotators also **manually created hints** for problems that originally lacked them.
7. The same annotators **assigned cateogries and subcategories** to all puzzles (see Table 1).
## Dataset composition
](https://arxiv.org/pdf/2505.10844)
## Citation
If you use this dataset, please cite our paper:
```bibtex
@article{han2025creativity,
title={Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models},
author={Han, Simeng and Dai, Howard and Xia, Stephen and Zhang, Grant and Liu, Chen and Chen, Lichang and Nguyen, Hoang Huy and Mei, Hongyuan and Mao, Jiayuan and McCoy, R. Thomas},
journal={Advances in neural information processing systems},
year={2025}
}
```
## Highlights
1. We introduce a **novel benchmark dataset**, BRAINTEASER, which uses brainteasers to evaluate the **reasoning abilities of LLMs**.
2. The Math and Logic datasets were curated by scraping problem-solving and reasoning questions from the [Braingle](https://www.braingle.com/brainteasers/All.html) website, an online platform of puzzles and brain teasers.
3. Authored by **expert problem solvers**, BRAINTEASER features diverse puzzle styles and complexities, aiming to **isolate models’ reasoning abilities rather than their memorization of formulas**.
4. BRAINTEASER is exclusively centered on **mathematical and logical puzzles**, all authored by expert problem solvers with demonstrated proficiency across a wide range of puzzle types.
5. As **quality control**, we conducted one round of **manual inspection** of all problems in BRAINTEASER done by college students who belong to a math club; these students have extensive experience in solving competition-level math problems.
6. During manual inspection, low-quality and ambiguously described problems were removed, leaving 242 Math and 236 Logic problems in the dataset. The same annotators also **manually created hints** for problems that originally lacked them.
7. The same annotators **assigned cateogries and subcategories** to all puzzles (see Table 1).
## Dataset composition
 ## Main observations
## Main observations
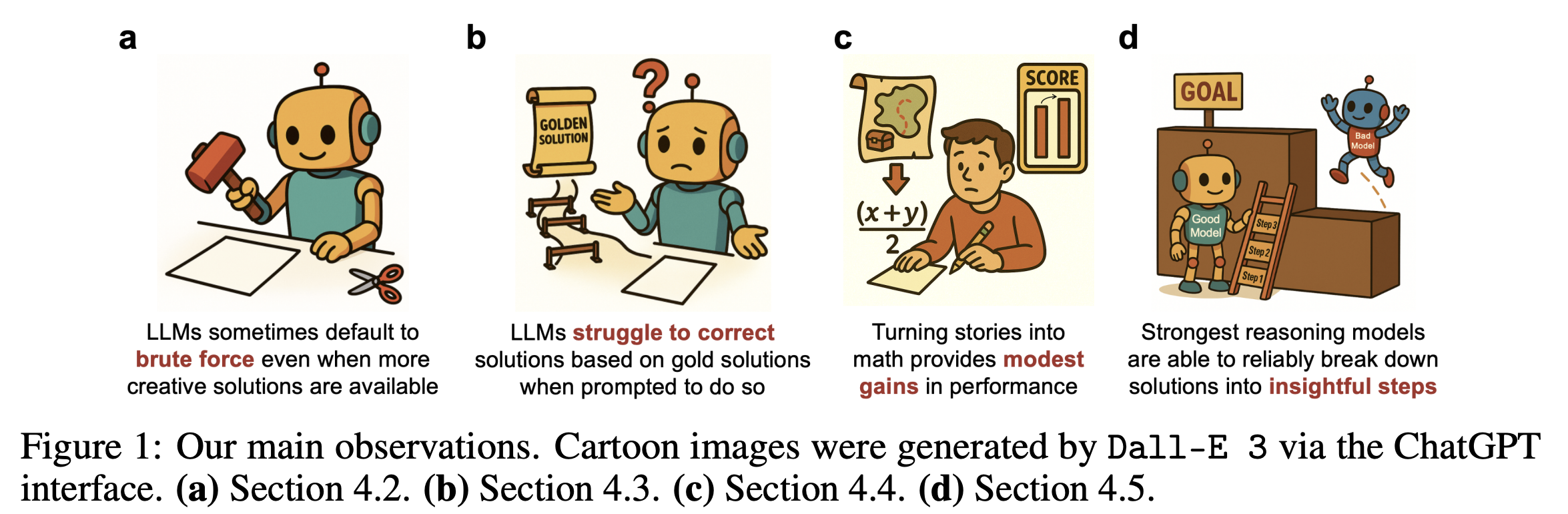 ## Creativity vs. Brute Force
## Creativity vs. Brute Force