---
language:
- en
- zh # 如果支持中英双语
license: apache-2.0 # 或 mit, other 等
base_model_relation: quantized
tags:
- image-generation
- multimodal
- qwen
- quantized
- nunchaku
- comfyui
library_name: diffusers # 或 diffusers 如果兼容
pipeline_tag: text-to-image # 或 image-to-image,根据实际
base_model: Qwen/Qwen-Image-2512 # 如果有上游模型,填 repo id
---
# QuantFunc
🤗 Hugging Face |
🤖 ModelScope |
💬 WeChat (微信) |
🎮 Discord
## Introduction
We are excited to share our latest model series based on nunchaku + qwen-image-2512 quantization. These models are carefully optimized to maintain high-quality output while significantly improving inference speed and efficiency. All models are 100% compatible with the nunchaku-comfyui && lora plugin and can be used directly in ComfyUI.
## Gallery
## Model Checkpoints
| Name | low_rank | Notes |
|:---|:---:|:---|
| nunchaku_qwen_image_2512_best_quality_fp4 | 256 | Best quality model, suitable for scenarios with extremely high quality requirements |
| nunchaku_qwen_image_2512_best_quality_int4 | 256 | Best quality model, suitable for scenarios with extremely high quality requirements |
| nunchaku_qwen_image_2512_ultimate_speed_int4 | 32 | Ultimate speed model, prioritizing inference speed |
| nunchaku_qwen_image_2512_ultimate_speed_fp4 | 32 | Ultimate speed model, prioritizing inference speed |
| nunchaku_qwen_image_2512_balance_int4 | 128 | Balanced model, achieving the best balance between quality and speed |
| nunchaku_qwen_image_2512_balance_fp4 | 128 | Balanced model, achieving the best balance between quality and speed |
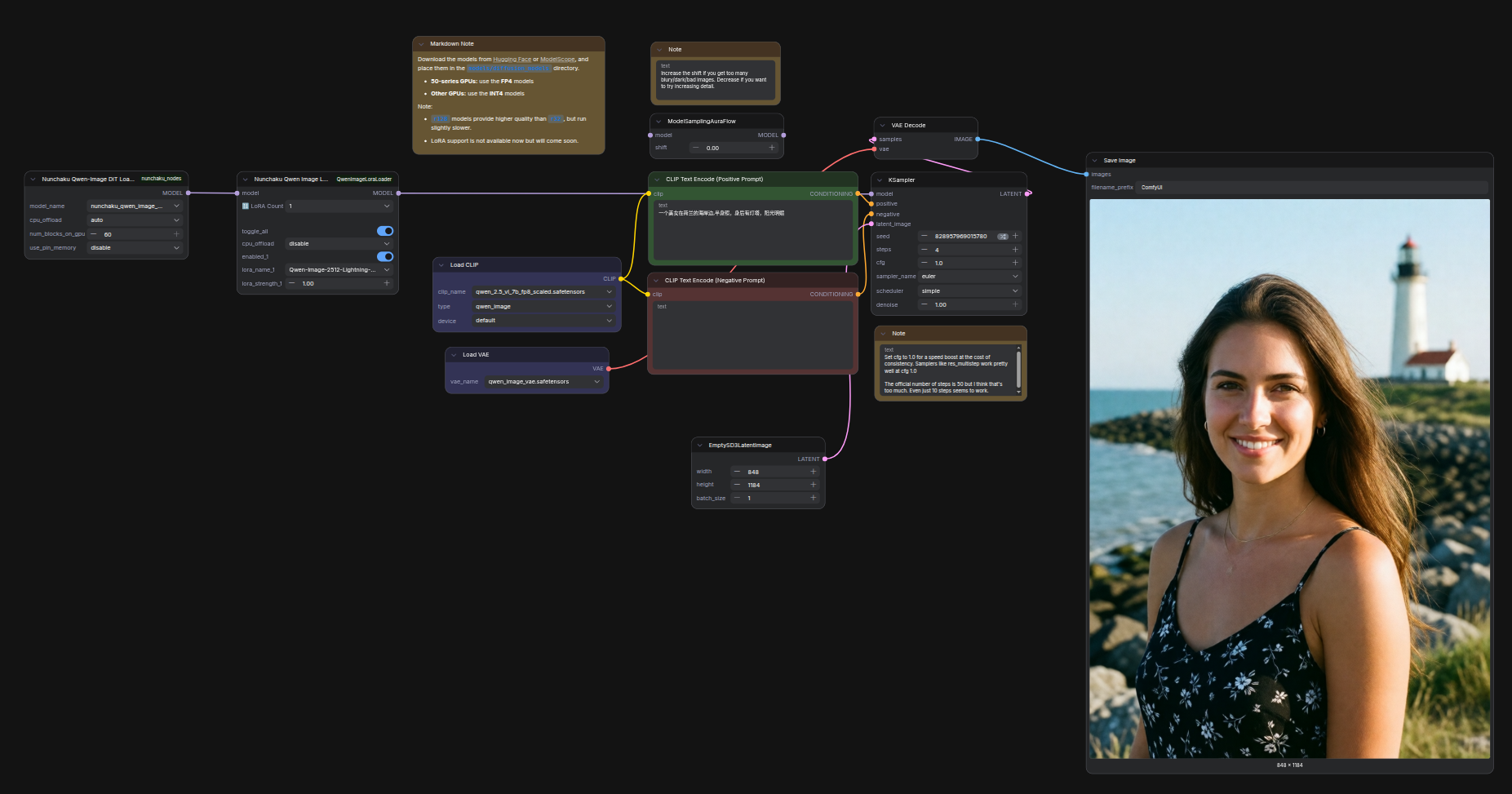
## 4 steps workflow
Here’s a workflow example of integrating 4-step LoRA in ComfyUI. If you don’t need 4-step LoRA, simply remove the LoRA node.
 ## Coming Soon
If you encounter any issues during use, feel free to join our community for feedback:
- Join our [Discord server](https://discord.gg/jCp9TpFWcn)
- Scan the QR code below to join our WeChat group
We will add support for build in lora and qwen-image-edit-2511 in approximately one month.
## Coming Soon
If you encounter any issues during use, feel free to join our community for feedback:
- Join our [Discord server](https://discord.gg/jCp9TpFWcn)
- Scan the QR code below to join our WeChat group
We will add support for build in lora and qwen-image-edit-2511 in approximately one month.






